
Algorithmen und Datenstrukturen in PASCAL Teil 10: Sortiermethoden C
In der heutigen, letzten, Folge von Algorithmen und Datenstrukturen geht es noch einmal ums Sortieren. Und zwar um das Sortieren von Bändern. Special Guest Star wird dabei <Heapsort> sein, welches wir kurzerhand in unser heute behandeltes <Mergesort> integrieren werden.
Die Situation
Doch kommen wir zuerst zum eigentlichen Problem der heutigen Folge. Beim Sortieren mit Bändern liegt grundsätzlich folgendes Szenario vor: Es geht darum eine Anzahl von Daten zu sortieren, die derart zahlreich auftreten, daß die Hauptspeicherkapazität des Computers nicht ausreicht.
Eine Situation, in der man sich als ST User glücklicherweise sehr selten befindet. Immerhin kann es - Voraussetzung Festplatte - durchaus zu einem derartigen Fall kommen. In diesem Fall werden die reinen Arraysortiermethoden, die Sie bis jetzt kennengelernt haben, unwirksam. Diese leben nämlich alle von der kompletten Unterbringung der Daten im Hauptspeicher. Dummerweise besitzen die, bis jetzt verfügbaren, Betriebssysteme für unseren Lieblingsrechner aber noch nicht über eine virtuelle Speicherverwaltung, weshalb wir genötigt sind eine andere, algorithmische, Lösung für das Problem zu suchen.
Ansatz
Was bleibt uns aber noch, wenn der Hauptspeicher versagt ? Richtig ! Wir müssen irgendwie auf den Massenspeichern sortieren. Die prinzipielle Methode, die dazu angewandt wird, ist zweiphasig:
- Zunächst wird die zu sortierende Datei in mehrere, mindestens zwei, Einzeldateien zerlegt.
- Mischt man diese beiden Dateien wieder zu einer einzigen Datei zusammen, so ist es beim Mischen möglich die Reihenfolge der Elemente, entsprechend der Relation, auszurichten.
Dadurch entstehen, in der resultierenden Datei, sortierte Teilfolgen. Diese Teilfolgen nennt man Läufe, oder englisch Runs. Das Sortierverfahren nennt sich Mischsortieren, oder Mergesort. Benutzt man dabei ein starres Schema, beispielsweise können zunächst aus Einzelelementen Runs der Länge 2 erzeugt werden, so ergibt sich, durch mehrfache Ausführung der beiden Phasen, schließlich eine sortierte Datei. Die Runs durchlaufen dabei die Längen: 1, 2, 4, ..., n. Das sind trunc(log2(n)) Durchläufe durch das zweiphasige Schema. Deshalb ergibt sich, multipliziert mit den n Vergleichsoperationen beim Verschmelzen der Dateien, wieder ein Sortieralgorithmus der Ordnung O(n*log(n)). Diese Begebenheit, die sich in der letzten Folge eigentlich als Kriterium für einen hochwertigen Algorithmus erwiesen hat, fällt heute nicht so sehr ins Gewicht. Die Ursache dafür liegt darin begründet, daß wir mit Dateien (!) arbeiten wollen. Dies bedingt das die reinen Vergleichszeiten, gegenüber den Zugriffs- und Kopierzeiten, zwar nicht vernachlässigt werden sollten, allerdings auch nicht so ausschlaggebend sind, wie beim Sortieren im Hauptspeicher.
Bevor wir ans Implementieren gehen, empfiehlt es sich daher, zunächst noch einen bisher unbeachteten Aspekt zu berücksichtigen.
Ich spreche von der Teilsortierung der betrachteten Datei.
Geht man nicht mehr von einer starren Länge der Runs aus, sondern betrachtet einen Run einfach als eine aufsteigend sortierte Folge von beliebig vielen Elementen, so kann man beim Zerlegen sämtliche derartigen Teilfolgen, ungeachtet ihrer Länge, auf das entsprechende Ausgabeband kopieren. Beim Verschmelzen der Ausgabebänder ergeben sich dadurch wiederrum längere Runs und sofort ...
Die dabei anfallenden zusätzlichen Vergleichsoperationen, zur Bestimmung der Runbegrenzungen, fallen weniger ins Gewicht, da die eingesparten Dateioperationen, wie oben bereits erwähnt, sehr viel zeitintensiver sind.
Das zugehörige Verfahren nennt sich natürliches Mischsortieren. Die Runs werden in diesem Fall auch als natürliche Runs bezeichnet.
Mischsortieren im Speicher
Obwohl eigentlich nicht beabsichtigt, haben wir, wegen der günstigen Komplexität (O(n*log(n)) von Mergesort, auch gleichzeitig eine höhere Sortiermethode für Datenmengen im Speicher gefunden. Vorzugsweise natürlich für Listen, mit denen sich sehr leicht die Aktionen einer Diskettendatei simulieren lassen. Deshalb betrachten wir zunächst einen Ansatz für das natürliche Mischsortieren, bei dem Listen verwendet werden.
Die dabei notwendigen Typen (Listing 10a) kennen Sie bereits in dieser, oder sehr ähnlicher, Form aus Folge 3, da ging es ja gerade um Listen. Es liegt unser üblicher Typzerfall (key/data) und eine rekursive Listendefinition vor (next).
Zerlegung der Listen
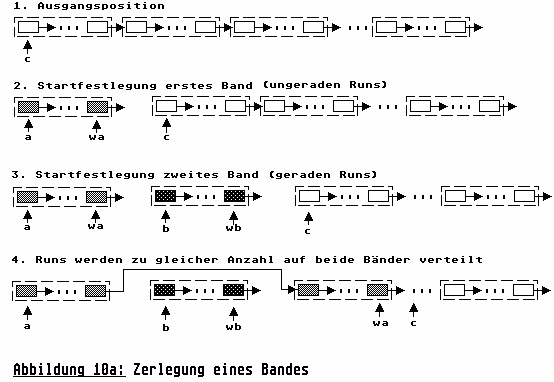 Zum Verständnis des Zerlegungsalgorithmus, betrachten Sie nun bitte Abbildung 10a. Position 1 zeigt unsere Ausgangslage: Wir besitzen eine Liste mit Namen c. In dieser existiert eine unbestimmte Anzahl von natürlichen Läufen mit einer unbestimmten Anzahl von Elementen je Lauf. Aufgabe ist es nun diese Läufe zu gleichen Teilen aufzuspalten. Dabei werden wir so vorgehen, daß die ungeraden Läufe (1,3,5,...) der Teilliste a zugeordnet werden und die geraden Läufe (2,4,6,...) der Teilliste b.
Zum Verständnis des Zerlegungsalgorithmus, betrachten Sie nun bitte Abbildung 10a. Position 1 zeigt unsere Ausgangslage: Wir besitzen eine Liste mit Namen c. In dieser existiert eine unbestimmte Anzahl von natürlichen Läufen mit einer unbestimmten Anzahl von Elementen je Lauf. Aufgabe ist es nun diese Läufe zu gleichen Teilen aufzuspalten. Dabei werden wir so vorgehen, daß die ungeraden Läufe (1,3,5,...) der Teilliste a zugeordnet werden und die geraden Läufe (2,4,6,...) der Teilliste b.
Dazu werden insgesamt fünf Zeiger benutzt:
Der Zeiger c markiert jeweils die Anfangsposition der noch verbliebenen, aufzuteilenden Restliste. Die Zeiger a und b markieren die beiden Startpositionen der Teillisten. Einmal gesetzt, bleiben sie während des gesamten Aufspaltungsprozesses fest. Last but not least, übernehmen die beiden Zeiger wa und wb die Markierung der Endpositionen beider Teillisten, also genau der Stellen an der Elemente aus c eingefügt werden können.
Wenn wir uns nun der Realisierung des Aufspaltvorgangs zuwenden (Listing 10b, Zeilen 13-65), so besteht das zerlegen, im Wesentlichen, aus einer Routine, die die Abmessung der natürlichen Läufe vornimmt (shift) und dabei jeweils den Zeiger l, synonym für c, entsprechend verrückt und die Endemarkierung für die abgespaltene Teilliste errechnet. Dabei wird der Zeiger l solange vorgerückt, bis ein Element gefunden wird, welches nicht mehr in den Lauf gehört (Zeile 35). In diesem Fall ist dann die Endemarkierung entsprechend zu setzen. Unmöglich verkompliziert wird dieser einfache Vorgang durch den Listenlookahead, also die Tatsache, daß wir die Liste voraus-schauend durchlaufen müßen, um noch die Endemarkierung der Teilliste zu berechnen. Was also einer ganz einfachen Begebenheit entspricht, wird durch die notwendigen Fallunterscheidungen und Listenwächter recht kompliziert. Sie können mir glauben, daß mich diese Routine beim Testen ganz schön Nerven gekostet hat. (Ungefähr für zwei Stunden Nerven.)
Die Kernroutine, des Zerlegungsalgorithmus, beschränkt sich nun auf den wiederholten Aufruf der Prozedur shift, bishin zu dem Punkt, wo die Liste c vollständig entleert ist. Dabei ist lediglich zu berücksichtigen, daß zu Beginn dieser Routine die beiden Listenstartmarkierungen, a und b, gesetzt werden.
Beachtenswert ist dabei, daß bei dem gesamten Vorgang nicht ein einziges Listenelement kopiert wird, sondern nur Zeigerumsetzungen vorgenommen werden.
Wie Sie noch feststellen werden, trifft dies ebenfalls auf das Verschmelzen zu.
Verschmelzen der Listen
Die Abbildung 10b stellt generell den Verschmelzungsvorgang dar. Indem aus den beiden Teillisten, a und b, jeweils die Elemente ausgewählt werden, die zur Erzeugung eines Laufes notwendig sind, wird die Liste c schrittweise wieder zusammengesetzt. Ist eine der beiden Listen a oder b vollständig entleert, so ist die andere Liste an das Ende der Liste c anzuhängen.
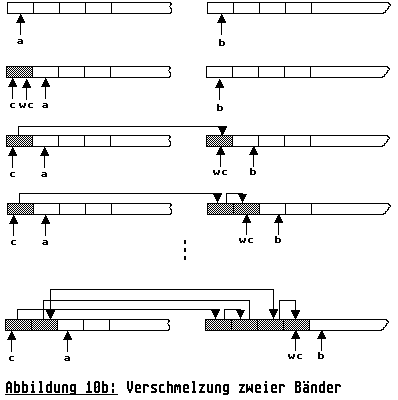
Die Implementierung dieses Vorgangs ist in den Zeilen 67-125 des Listings 10b (verschmelze) vorgenommen worden. Dabei fällt auf, daß der Verteilungsvorgang eine große Anzahl von Fallunterscheidungen notwendig macht, um die jeweiligen Laufbegrenzungen sicherzustellen, sowie die für die Länge der Teilläufe optimalen Startelemente auszuwählen.
Im Detail:
Da es unser Ziel ist, die Läufe aufsteigend zu sortieren, ist vor Beginn der eigentlichen Zerlegungsschleife (Zeilen 96-124) sicherzustellen, daß die Zerlegung mit dem minimalen Element der beiden Teillisten beginnt (Zeilen 83-94). Dabei wird auch gleich gewährleistet, daß die Start- und Endemarkierungen der Gesamtliste - c und wc - initialisiert werden.
Um nun eine optimale Elementabfolge zu gewährleisten, sind insgesamt acht (!) Fallunterscheidungen notwendig:
- Liste a ist leer (Zeile 97)! In diesem Fall erreicht man die Verschmelzung, indem Liste b an das Ende von c angehängt wird.
- Liste b ist leer (Zeile 103)! Vollständig analog wird nun a an c angehängt und das Verschmelzungsverfahren terminiert ebenfalls.
- Keine der beiden Listen ist leer (ELSE-Zeig von 2.), dann ist die eigentliche Verschmelzung vorzunehmen!
a) Der Schlüssel von Element a ist größer oder gleich dem letzten Schlüssel von c (Zeile 109). In diesem Fall ist a ein möglicher Kandidat für die Liste c. Für den Fall das b günstiger ist (Zeilen 110+111) wird b nach c kopiert (Zeile 112).
b)+c) Andernfalls, entweder wenn a günstiger ist (Zeile 116), oder wenn b überhaupt nicht in Frage kommt (Zeile 114), wird a nach c kopiert.
d) Kommt Element a nicht in Frage (Zeilen 118-124), so ist b auf seine Runzugehörigkeit zu überprüfen (Zeile 118) und wird gegebenenfalls überspielt.
e) Wiederrum andernfalls ist der Run beendet und es ist nun das günstigste Element für den Start des neuen Runs festzu legen (Zeile 121). Dieses ist genau dann a, wenn a kleiner als b ist.
f) Ansonsten wird b als neuer Runstart angenommen.
Wie Sie oben, nach der Bearbeitung durch einen freundlichen Textsetzer, hoffentlich noch erkennen, kann man auch in Umgangssprache strukturiert programmieren. Der Transfer auf die bezeichneten Programmstellen ist dann natürlich sehr leicht zu vollziehen.
Die Mergesort- Kernroutine
Ebenfalls leicht zu vollziehen, ist die Umsetzung von mergesort (Zeilen 127-145) mit den beiden gerade behandelten Prozeduren zerlege und verschmelze. Sie sind lediglich abwechselnd, zunächst zerlege, dann verschmelze, aufzurufen. Erhält man bei der Zerlegung eine leere Liste, so ist das Verfahren zu beenden. Das Ergebnis steht dann in der jeweils anderen Liste und ist noch dem Ergebnisparameter l zuzuweisen.
Ein Beispiel für den gesamten Mergesort-Vorgang finden Sie in Abbildung 10c. Man sieht wie die Liste durch die beiden oben beschriebenen Vorgänge nach und nach immer längere Runs ent-wickelt und schließlich vollständig sortiert ist.
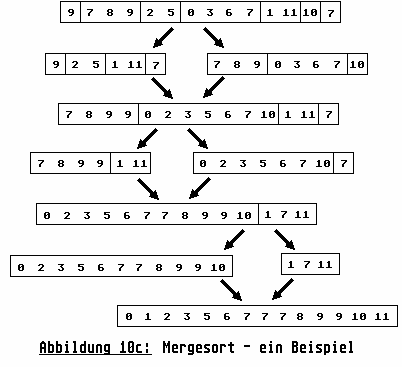
Auf eine Besonderheit, der Sortierung mit natürlichen Läufen, möchte ich Sie auch noch hinweisen: Betrachten Sie doch bitte einmal die letzten beiden Runs, der rechten Teilfolge, in der ersten Zerlegung. Sie sehen wie hier aus ursprünglich zwei Runs zur Zerlegungszeit - (0, 3, 6, 7) einerseits und (10) andererseits - ein einziger Run zur Verschmelzungszeit wird. Eine kleine Zugabe, die unserer Sortierzeit nur recht sein kann.
Apropos Sortierzeit! Die Messungen an Mergesort im Speicher ergaben Werte, die, wie zu erwarten war, die primitiven Arraysortiermethoden lang hinter sich gelassen haben, allerdings doch sehr deutlich unter denjenigen der höheren Sortiermethoden für Arrays liegen. Aber es war ja auch nicht unsere Intention, quicksort und Anverwandte zu schlagen.
Zwei Testutilities
Zum Testen von mergesort, finden Sie zum Ende des Listings 10b noch die beiden Prozeduren list_ausgabe (Zeilen 147-156) und make_random (Zeilen 158-180).
Wie bisher meistens: Nomen est omen ! list_ausgabe schreibt die Listenelemente in der Reihenfolge ihres Erscheinens in die Standardausgabe und make_random erzeugt eine Liste mit anz zufällig gewählten Komponenten.
Mischsortieren mit Dateien
Kommen wir nun zu unserer heutigen Hauptaufgabe: Der Übertragung des obigen Konzeptes auf einen dateiorientierten Algorithmus.
Die Typen (Listing 10c) machen dabei keine besondere Mutation durch. Lediglich der Zeiger list wird durch das FILE datei ersetzt.
Wenden man sich nun dem eigentlichen Programmtext (Listing 10d) zu, so stellt man fest, daß er gleich auf den ersten Blick einfacher wirkt, als der äquivalente Programmtext mit Listen. Diese Tatsache liegt darin begründet, daß wir uns beim Handling mit Dateien keine Gedanken über eine Startmarkierung, etwa wie bei den Listen, machen müssen. Dadurch fallen einige Fallunterscheidung, insbesondere für die Behandlung von leeren Listen, weg.
Dagegen kommt hinzu, daß man sich, sowohl beim Zerlegen, als auch beim Verschmelzen, den Schlüssel des letzten geschriebenen Elementes (min) selbst merken muß, da er durch put(c) verloren geht und nicht mehr für Vergleichsoperationen zur Verfügung steht.
Eine weitere Änderung ist der Tatsache zuzuschreiben, daß wir bei Dateien nicht mehr ganz so einfach einen Check auf das Fehlen von Elementen vornehmen können, wie dies bei den Listen der Fall war. Aus diesem Grund ist die Feststellung der Abbruchbedingung, für das Verfahren, der Funktion zerlege übertragen worden. Diese gewinnt durch reset der beiden Teilfolgendateien und anschließenden Test auf das Dateiende die notwendige Information.
Was es ebenfalls noch zu beachten gilt, ist die Tatsache, daß unser Algorithmus jetzt, Dank (oder Fluch) seiner beiden Teilfolgedateien, zeitweise doppelt soviel Platz auf den Massenspeichern einnimmt, wie die ursprüngliche Datei besessen hat. Bei gefüllten Massenspeichern, ist also noch auf ausreichend Platz zu achten. Die nächste Enttäuschung steht bevor, wenn man größere Datenmengen, und dann wohlmöglich noch auf Diskette, sortieren möchte. Dabei tretten, durch die auftretenden Dateizugriffe, völlig unakzeptable Sortierzeiten auf.
Was tun ?
Das Problem liegt in den vielen Zerleg/Verschmelz- Durchläufen, die bis zur endgültigen Sortierung benötigt werden. Könnte man die Länge der Runs deutlich verlängern, so würden auch die Durchläufe drastisch reduziert. Der Schlüssel zur Lösung des Problems, liegt in der Nutzung einer internen Sortiermethode, zwecks Verlängerung der sortierten Teilfolgen beim Zerlegen. Dabei wird jeweils eine bestimmte Menge von Daten in einen Pufferarray eingelesen und sortiert. Zusammen mit den noch ankommenden restlichen Elementen, kann man dann diese sortierte Teilfolge abmischen und erhält somit eine wesentlich verbesserte Runlänge.
Besonders Heapsort eignet sich sehr zu diesem Zweck. Dabei wird, zur Erzeugung eines Runs, 3-schrittig vorgegangen:
- Zunächst wird eine gewisse Anzahl (Das Minimum aus vorhanden Elementen und Arraygröße) Elemente in den Array geladen und in einen Heap - hier Minimumheap - überführt.
2.a. Falls das Ende des Eingabebandes erreicht ist, oder das oberste Eingabelement kleiner, als das oberste Heapelement ist, so läßt sich dieses Element nicht mehr in den Run einbauen.
b. Andernfalls ist das oberste Heapelement auszugeben; das oberste Eingabelement an seine Stelle zu setzen und die Heapeigenschaft zu korrigieren. Punkt 2 wird im Anschluß darauf iteriert. - Nach Abbruch durch Punkt 2a ist noch der restliche Heap auf das Ausgabeband abzumischen.
Bei der Implementierung (Listing 10e) fallen die entsprechenden Änderungen nur in der Unterroutine shift an. Denn, Aufgabe von shift war ja gerade das Erzeugen eines Runs. Zur Verwaltung des Heaps benutzen wir die, Ihnen bereits be-kannte, Prozedur korrigiere. In ihr sind, im Gegensatz zu Heapsort, lediglich die Relationen umgedreht, um nun, statt einem Maximumheap, einen Minimumheap zu erzeugen. Weiterhin sind leichte Namensänderungen, zur Anpassung an das Problem, vollzogen worden. In shift werden nun die oben beschriebenen drei Punkte vollzogen. Ihre Zuordnung zu den Programmtext dürfte keine Schwierigkeiten bereiten:
- Zeilen 72-87: Füllen des Arrays und Erzeugen der Heapeigenschaft
- Zeilen 89-100: Filterung der Eingabedaten durch den Heap, daher auch die Bezeichnungen Heapfilter, bzw. Natürliches Mischsortieren mit Heapfilter, für Hilfsmittel und Verfahren.
- Zeile 101 & Prozedur spool_heap: Abmischen der restlichen Heapelemente.
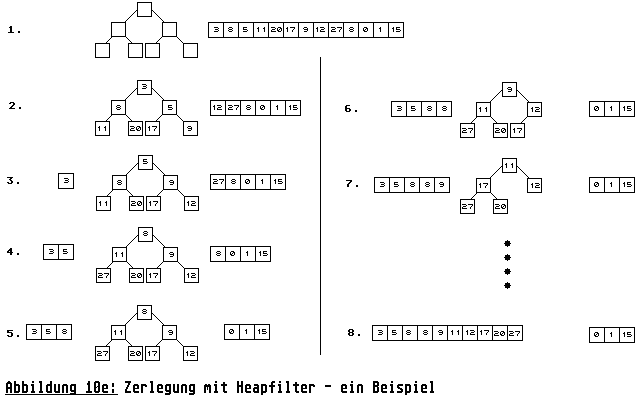
Um diese drei Vorgänge etwas transparenter zu machen, wollen wir noch ein Beispiel (Abbildung 10e) durchgehen:
Punkt 1 zeigt unsere Ausgangsposition: den leeren Heap und ein gefülltes Eingabeband. In Punkt 2 ist der Array gefüllt worden und die Heapeigenschaft hergestellt. Punkt 3, 4 und 5 zeigen, wie zunächst die Elemente 3, 5 und 8 aus dem Heap entnommen werden und wie jeweils ein Element aus dem Eingabeband sie im Heap ersetzt. Dieser wird darauffolgend jeweils korrigiert. Ab Punkt 5 ist die Übernahme von Elementen aus dem Eingabeband nicht mehr möglich, weil das anliegende Element 0 nicht mehr in den Run aufgenommen werden kann. Es wird damit begonnen den Heap abzumischen (Punkte 5-8). Als Ergebnis erhält man einen Run, der mindestens die Größe des Heapfilters als Länge besitzt.
Verbessern läßt sich dieses Verfahren nun noch, indem man nicht, wie bisher, nur auf zwei Bänder abmischt, sondern stattdessen auf mehrere Bänder, sagen wir k. Dadurch kann man, beim Verschmelzen, größere Runs erzeugen, indem von jedem der k Bänder jeweils ein Run zur Erzeugung eines langen Runs auf dem Ausgabeband herangezogen wird.
In der Literatur, zumeist der älteren, lassen sich zur Verbesserung von Mergesort tatsächlich die wildesten Ansätze, in diese Richtung, finden. Dabei gilt es aber auch zu berücksichtigen, daß Sortierverfahren auf der Basis von Bändern, wohl doch ihren Zenit überschritten haben, da die heute üblichen leistungsfähigen Maschinchen - mehr oder weniger liebevoll können Sie jetzt Ihre Blicke in Richtung ST lenken -, mit ihren großen Hauptspeichern, den intensiven Gebrauch von Mischsortierverfahren nicht gerade förderlich sind. In diesem Sinne werde ich Ihnen auch weitere Ausführungen, die nur in noch längeren Programmen ausarten würden, ersparen, zumal mit unserem Zweibänder Heapfilter Mischsortieren schon recht brauchbare Ergebnisse erzielt werden können (und recht lange Verfahrensnamen angegeben werden müssen).
Zum Abschluß
Damit wären wir heute glücklich am Ende dieser Folge und auch der Serie angekommen. Im nächsten Monat werden Sie sicherlich eine andere höchst interessante Serie an dieser Stelle vorfinden.
Indessen hoffe ich, daß Ihnen meine Ausführungen, im hinter uns liegenden Serienjahr (Fast wie in Dallas), zu den doch zumeist recht abstrakten Themen, einige Anregungen zur eigenen Programmierung gegeben haben. Da die Ausarbeitung zu dieser Serie aber zumindestens mir großen Spaß bereitet hat, habe ich mich, nicht zuletzt auf Anregungen aus dem Heimverlag, dazu motivieren lassen, das Thema noch einmal, in größerem Kontext und in Buchform, aufzugreifen.
In diesem Sinne, vielleicht sieht/ließt man sich ja doch mal wieder, bis dann,
Dirk Brockhaus