Vieles in der öffentlichen Diskussion um Computer und deren Einsatz in Verwaltung und Industrie in der Bundesrepublik erinnert an obigen Stoßseufzer. Stimmt die Vision von der den Menschen ersetzenden Maschine? Verdrängen die Computer den Menschen nun auch noch aus seinem letzten Schlupfwinkel egozentrischer Selbstherrlichkeit? Gibt es bald denkende, sehende, hörende, sprechende, fühlende, intelligente Maschinen? Ant-| wort (nicht von Radio Eriwan): im Prinzip ja. Allerdings nicht ganz so schnell, wie Science Fiction Autoren es uns weismachen wollen. Und brauchen wir intelligentere Computer? Ja! Erstens, weil sie einfach nützlicher sind, und zweitens, weil wir bei der Implementation künstlicher Intelligenz auch etwas über unsere eigene Gehirnstruktur erfahren. Wo der Stand der Forschung zur Zeit ist, versucht dieser Artikel darzulegen. Der Ausgangspunkt hierzu war das Erscheinen der XLISP Versionen und des PROLOG Interpreters in der Public Domain Software für die ATARI ST Computer. Zu beiden Programmen werden Folgeartikel erscheinen, die sich mit den beiden „Muttersprachen“ der künstlichen Intelligenz unter besonderer Berücksichtigung der für den ST Programmierer zur Verfügung stehenden Versionen beschäftigen.
Intelligenz und Computer?
Unter Inteligenz versteht man im allgemeinen die Fähigkeit, sich einer veränderten geistigen Umgebung anzupassen. Erkennbar wird der Unterschied zwischen intelligentem (kognitivem) und mechanischem (unbewußtem) Handeln, wenn die Voraussetzungen, die eine Handlung sinnvoll erscheinen lassen, sich ändern. Ändert sich nun bei gleichem Auslösereiz die Reaktion des untersuchten Objekts, dann kann man von einem intelligenten Verhalten sprechen. In der Natur gibt es viele Beispiele für Verhalten, die bei erstem Hinsehen den Eindruck hoher Intelligenz erwecken, bei Veränderung der Situation jedoch haargenau gleich ablaufen. Die Verhaltensforscher sprechen dann von angeborenen auszulösenden Mechanismen. Diese haben sich im Laufe der Evolution als für eine bestimmte Spezies nützlich erwiesen, erlauben dem Individuum jedoch keine Abweichung vom ererbten Verhaltensschema, so unsinnig das ablaufende Verhalten in einer bestimmten Situation auch sein mag. Und dies ist genau die Situation, in der sich normalerweise ein Computer befindet. Der Programmierer stellt aus einem vom Hersteller implementierten Befehlssatz ein Programm zusammen, das eine bestimmte Aufgabe auf eine vom Programmierer festgelegte Art und Weise (dem Algorithmus) löst. Je erfahrener der Programmierer, desto mehr Ausnahmesituationen wird er beim Entwurf des Programms bereits vorsehen. Dennoch kann ein auf diese Art programmierter Computer keine im obigen Sinn intelligente Leistung vollbringen, weil er eben nicht anders reagieren kann, als vom Programmierer (bewußt oder unbewußt) vorgesehen wurde. Von einem intelligenten Computer müßte man hingegen erwarten können, daß sich sein Verhalten mit zunehmender Betriebszeit sinnvoll (positiv) ändert.
Imperative und applikative Sprachen
Aus dem oben Gesagten geht wohl klar hervor, daß die traditionellen Sprachen für die Programmierung von Problemen, die Intelligenz erfordern, nur im begrenzten Maße effektiv sind. Zu diesen Sprachen zählen Assembler, BASIC, C, FORTH, FORTRAN oder PASCAL, um nur einige der bekanntesten zu erwähnen. All diese Sprachen haben gemeinsam, daß der Programmierer mit Hilfe der jeweils zur Verfügung stehenden Syntax einen Algorithmus erarbeitet, der vom Computer dann schrittweise abgearbeitet werden muß. Der Programmierer übernimmt die Funktion eines Alleinherrschers, dem kein Widerspruch entgegenkommt, die benutzten Sprachen nennt man imperativ. Wie die Verbreitung dieser Sprachen zeigt, kann man mit ihnen ganz gut leben, solange sich die Anwendung im traditionellen Aufgabengebiet der Computer bewegt: Rechnen und Verwalten. Beiden Aufgabengebieten ist gemeinsam, daß eindeutige Lösungen und Lösungswege für die möglichen Fragestellungen existieren. In der Tat sind die ersten Computer ja auch als Rechenkünstler für die Berechnung von Flugbahnen militärischer Objekte konstruiert worden, um die mangelhaften rechnerischen Fähigkeiten des Homo Sapiens wirkungsvoll erweitern zu helfen. Es ist eben ganz einfach so, daß die Rechenfähigkeit zum Überleben der Menschheit offensichtlich nicht ganz so nützlich war wie andere Fähigkeiten des menschlichen Intellekts. So ist es dann auch nicht weiter verwunderlich, wenn genau die Fähigkeiten, die uns so leicht von der Hand gehen, wie z. B. Sprache verstehen, Bilder erkennen, zielorientiert agieren, dem Computer ungeheure Schwierigkeiten bereiten. Diese intelligenten, menschlichen Fähigkeiten verlangen nämlich, daß aus verwaschen definierten Ausgangssituationen und mehrdeutigen Aktionsmöglichkeiten zu einer oder mehreren Zielsituationen gefunden wird. Dem Computer all das beizubringen, was dem Menschen aufgrund seines Weltwissens leichtfällt, ist (etwas überspitzt) das Problem der künstlichen Intelligenz. Es ist klar, daß sich die Informatiker hierzu neuer Sprachen bedienen, die nicht mehr imperativ sondern applikativ bzw. deklarativ genannt werden. Die bekanntesten Vertreter sind (reines) LISP und PROLOG. In diesen Sprachen hat der Programmierer keinen Algorithmus mehr zu beachten. Vielmehr legt der Programmierer eine Softwarewelt aus Regeln und Schlußfolgerungen fest. Er bestimmt also nur noch die Struktur des zu lösenden Problems. Die eigentliche Lösung von Fragestellungen besorgt dann ein (in den Compiler oder Interpreter bereits integrierter) Backtracking Algorithmus. LISP ist die älteste Kl-Sprache schlechthin und existiert in vielen Versionen, von denen in den meisten auch reichlich imperative Sprachelemente vorhanden sind. PROLOG ist erst in das Bewußtsein der Computeröffentlichkeit gelangt, nachdem die Japaner in einem Report 1986 [14] diese in Europa [4] entwickelte Sprache als Basissprache ihrer fünften Computer-Generation gewählt hatten. Nach diesem „Computer Pearl Harbour“ ist PROLOG schlagartig ins Licht der Öffentlichkeit gerückt worden, und seit etwa einem Jahr sprudeln in den USA die verschiedenen Compiler und Interpreter für Microcomputer auf den Markt. Mit beiden Sprachen werde ich mich ausführlicher in einigen Lolgeartikeln beschäftigen.

Bisherige Anwendungen
Der umfassendste Überblick über die bisherigen Aktivitäten der KI-Forschung ist wohl in dem Werk von Barr und Feigenbaum [1] zu finden. Ich möchte hier kurz einige Teilbereiche und deren Hauptprobleme an-reißen.
Strategische Spiele
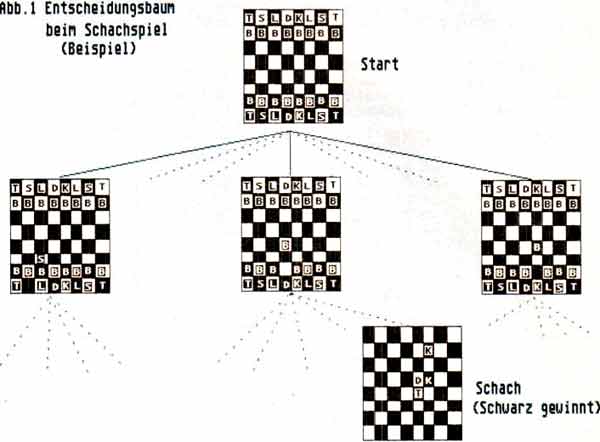
Am eindrucksvollsten ist der Fortschritt in der KI sicherlich im Bereich des Schachspiels. Es muß aber ausdrücklich darauf hingewiesen werden, daß im Verlauf der Entwicklung von Schachprogrammen ein radikales Umdenken erforderlich war. Erste Programme versuchten, das Spiel mit roher Gewalt zu gewinnen. Dazu mußte der Computer einfach die sich im Verlauf des Spiels ergebenden Entscheidungsbäume soweit wie möglich im voraus berechnen (Abb. 1). Man ging davon aus, daß höhere Rechenleistung und Speicherkapazität zusammen mit optimierten Such- und Sortieralgorithmen zu der gewünschten Schachleistung führen würden. Daß diese Erwartungen zutiefst enttäuscht wurden, liegt an einem Effekt mit der wohlklingenden Bezeichnung kombinatorische Explosion. Wie man Abb. 1 entnimmt, verästelt sich der Entscheidungsbaum nach jedem Zug (fachchinesisch: Knoten im Baum) in so viele Zweige, wie der Gegner zulässige Züge besitzt. Und das sind gerade im Mittelspiel sehr viele. Nach einer Schätzung von C. Shannon beträgt die Anzahl der möglichen Stellungen auf einem Schachbrett (der Knoten im Schachbaum) ca. 10120; das ist eine 1 mit 120 Nullen! Man muß schon einen sehr guten Computer haben, um diese Zahl überhaupt speichern zu können. In BASIC geht’s jedenfalls nicht. Hätte man einen Supercomputer, der pro Sekunde 1 Million Stellungen bewertet, so wären zur vollständigen Durchrechnung noch 10114 Sekunden erforderlich. Das sind mehr als 10106 Jahre. Unser Universum existiert aber erst ca. 10'° Jahre. Das heißt, Sie können getrost 1096 mal die Entwicklung des Universums an sich vorbeiziehen lassen, bis unser hypothetischer Supercomputer alle möglichen Schachstellungen durchgerechnet hat. Nach dieser schmerzlichen Erkenntnis hat man den Schachmeistern auf die Finger geschaut und sich der Bedeutung von Erfahrung erinnert, die sich in Form von Merkregeln manifestiert ('Bauer am Rand ist eine Schand'). Solche nicht mathematisch ableitbaren Lösungsverfahren werden in der Informatik Heuristik genannt.
Spracherkennung und Sprachverarbeitung
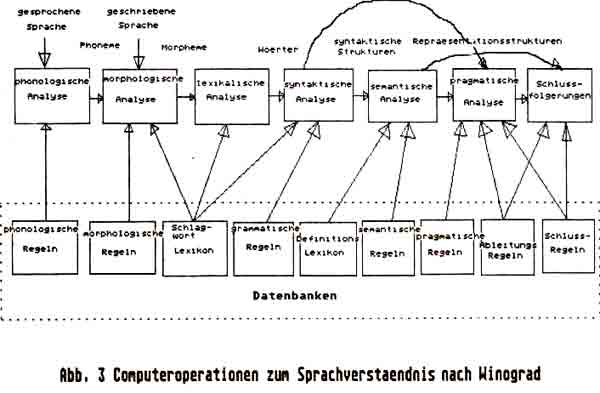
In diesen Bereich fallen die Anstrengungen zur maschinellen Übersetzung von Texten mit korrekter Grammatik. Es ist amüsant zu lesen, daß im sogenannten Gordon-Helmer-Bericht von 1964 [16] die Einführung solcher Programme bereits für 1978 vorausgesagt wurde. Der Hauptgrund für die unerwartet hohen Schwierigkeiten im Bereich der Sprachübersetzung liegt in der Mehrdeutigkeit menschlicher Sprache, die zu Mißverständnissen oder völligen Fehlinterpretationen führt. Der Standard-Demo-Satz 'Ich beobachte die Mädchen auf dem Hügel mit dem Fernglas’ ist ein Beispiel für die Mehrdeutigkeit menschlicher Sprache. Ein Meilenstein bei der Entwicklung von Software zur Spracherkennung stellt das 1972 von Terry Winograd veröffentlichte Programm SHRDLU zum Verständnis natürlicher (englischer) Sprache dar [18]. Eine ausführliche Beschreibung des in LISP geschriebenen Programms findet sich auch in dem Lehrbuch von C. M. Hamann [8]. Abb. 2 zeigt die Grundstruktur dieses Programms. Die angegebenen Programme sind miteinander vernetzt und rufen sich gegenseitig rekursiv auf. Allerdings beschränkt sich die Unterhaltung auf eine Bauklötzchenwelt, in der der Computer Klötzchen verschiedener Farbe und Form greifen und an anderer Stelle wieder absetzen kann. Es ist trotzdem verblüffend zu lesen, welch 'intelligente’ Unterhaltung sich zwischen dem Programm und dem Bediener ergibt [18]. Vom selben Autor stammt die [19] entnommene Abb. 3, die die zum Sprachverständnis erforderlichen Computeroperationen darstellt. In dieser Abbildung sind die verschiedenen Wissensbasen schraffiert. Die Implementation der dargestellten Programmteile ist noch keineswegs vollständig entwickelt. Dennoch zeigt der in [7] abgedruckte Musterdialog aus dem Hamburger Rede-Partner-Modell (FLAM-RPM) gegenüber SHRDLU ein erstaunliches Sprachverständnis und Alltagswissen. Allerdings bezweifelt Winograd, daß Computer die Aufgabe der sprachlichen Analyse jemals vollständig lösen können. Vielmehr sieht er in dem Computer ein nützliches, strukturiertes sprachliches Medium, also ein Werkzeug.

Expertensysteme
Die bislang erfolgreichsten Beispiele aus dem Bereich der KI sind sogenannte Expertensysteme. Das sind Programme, die auf eine Datenbank mit Wissen aus einem meist eng umrissenen Aufgabengebiet zurückgreifen und Schlußfolgerungen ziehen können, die denen von menschlichen Experten auf diesem Gebiet durchaus ebenbürtig sind. Die bekanntesten Beispiele sind MYCIN und DENDRAL. MACIN ist ein Expertensystem zur medizinischen Diagnostik bakterieller Blutinfektion und wurde von Edward H. Shortliffe [3] von der Universität Stanford (USA) entwickelt. Die Wissensbasis verfügt über mehr als 500 empirische Regeln. Die Regeln haben die Form „Wenn Bedingungen dann Ergebnis mit Wahrscheinlichkeit.“ So ist es möglich, die Wahrscheinlichkeit einer Diagnose, die in mehreren Stufen deduziert (hergeleitet) wurde, nach den Gesetzen der Wahrscheinlichkeitsrechnung zu berechnen. Können auf verschiedenen Wegen mehrere Diagnosen deduziert werden, werden sich diese i. a. in ihrer Wahrscheinlichkeit unterscheiden und somit eine Auswahl unter den möglichen Diagnosen erleichtern. DENDRAL ist ein Expertensystem zur Bestimmung der Struktur organischer Moleküle aus dem Massenspektrum, der NMR, und anderer Verfahren. Abb. 4 zeigt, wie der Entscheidungsbaum durch die Anwendung heuristischer Verfahren reduziert wird. Dieses Programm wurde von E. A. Feigenbaum [13] ebenfalls in Stanford entwickelt. Expertensysteme lassen sich deshalb relativ leicht erstellen, weil die Umsetzung der Fragestellung in eine Form der formalen Logik relativ einfach ist. Und Lösungswege für Probleme der formalen Logik sind seit der Einführung der Resolutionsmethode durch J. A. Robinson im Jahre 1964 [15] bekannt. Die Resolutionsmethode ist eine Computervariante des in der Mathematik bekannten Verfahrens des indirekten Beweises, in dem die zu beweisende Aussage negiert und zu einem Widerspruch geführt wird.

Robotertechnik
Selbstverständlich ist die Entwicklung von KI untrennbar mit der Entwicklung von Handhabungsautomaten (Originalton DIN) verbunden. Die zur Zeit in der Anwendung befindlichen Industrieroboter sind nämlich ziemlich „dumm“ und verlangen viel Programmieraufwand. So kann es bei ungeschickter Programmierung Vorkommen, daß zu dicht plazierte Roboter ohne tiefere Erkenntnis auf sich einschlagen und sich gegenseitig zerstören. Vom idealen Roboter werden deshalb menschenähnliches Orientierungsvermögen, Tastsinn, Seh- und Hörvermögen verlangt. Daß zumindest das Sehvermögen KI verlangt, ist wohl klar, wenn man sich an die verschiedensten optischen Täuschungen erinnert, mit denen uns unser Gehirn immer wieder überrascht. Solche optischen Täuschungen haben ihre Ursache nicht in einer fehlerhaften Optik, sondern sind auf die komplexe Auswertungssoftware in unserem Gehirn zurückzuführen. In einem sehr interessanten Artikel in der Zeitschrift BYTE [5] erläutern die Autoren, wie sie mit Hilfe von auf Rahmen basierender Wissensrepräsentation ein einfaches visuelles Erkennungssystem in PROLOG implementiert haben (Quelltext inclusive!). Dieses Programmsystem ist in der Lage, die Architektur einfacher Serienhäuser zu erkennen und ggf. architektonische Verbesserungsvorschläge zu machen. Die Autoren betonen allerdings, daß ihr System von der geringen Modellzahl der untersuchten Serienhäuser profitiert. Es gibt dagegen ein universelles visuelles System namens ACRO-NYM, welches in Stanford (der Name kommt in diesem Aufsatz öfter vor) von T. Binford entwickelt wurde [2], Wesentlich mehr Schwierigkeiten bereitet den Forschern aber seltsamerweise die Entwicklung multipler Manipulatoren, wie sie. erforderlich sind, um feinmechanische Aktivitäten in den Griff zu bekommen. Für einen zweiarmigen Roboter stellt z. B. die Aufgabe, einen Bleistift waagerecht zwischen den „Fingern“ zu halten und dessen Enden gegenläufig kreisen zu lassen, ein enormes Problem dar. Zur Bewältigung dieser Aufgabe müssen nämlich eine Vielzahl sensorischer Daten in Echtzeit empfangen und koordiniert werden. Ein Gesamtkontrollsystem eines zukünftigen zweiarmigen intelligenten Roboters zeigt Abb. 5 [9]. Natürlich darf die selbständige Roboternavigation im Reigen der KI nicht fehlen. Man sieht ja manchmal schon Transportroboter durch menschenleere Fabrikhallen huschen, aber diese laufen allesamt in besonders präparierten Umgebungen. Ziel der autonomen Navigation ist es, einem Roboter beizubringen, in einem ihm unbekannten Raum vom momentanen Standpunkt aus zu einem vorgegebenen Ziel zu gelangen. Natürlich müssen evtl, vorhandene Hindernisse erkannt und umgangen werden. Außerdem sollte möglichst schnell der kürzeste Weg zum Ziel gefunden werden. Und falls der Roboter nun doch einmal in der Gegend herumirrt, sollte er wenigstens in der Lage sein, aus seinen Fehlern zu lernen und während seiner Erfahrt eine genauere Karte seiner Umgebung anfertigen [10]. Stand der Dinge sind Geräte mit der Leistung von HERMIES, einem PC auf Rädern mit einem Sonarsystem [11]. Abb. 6 zeigt, wie er sein Ziel erreicht. Die Hindernisse waren nicht einprogrammiert, sondern wurden im Verlauf der Bewegung geortet.

Und in Zukunft?
Es ist sicher klar geworden, in welch starkem Maße die Berücksichtigung von Faktenwissen zur künstlichen Intelligenz von Computern beiträgt. Ein wesentlicher Fortschritt in der KI-Forschung ist deshalb wohl auch erst dann zu erwarten, wenn sowohl Speichermedien für gigantische Wissensbasen (vielleicht CD-Disks?) als auch neue Methoden zur Bewältigung der Datenflut zur Verfügung stehen. Die Japaner haben deshalb 1982 in einer Konferenz die Grundlagen zur Entwicklung eines neuen Typs von Computer, dem vielgerühmten Computer der fünften Generation, festgelegt [14].
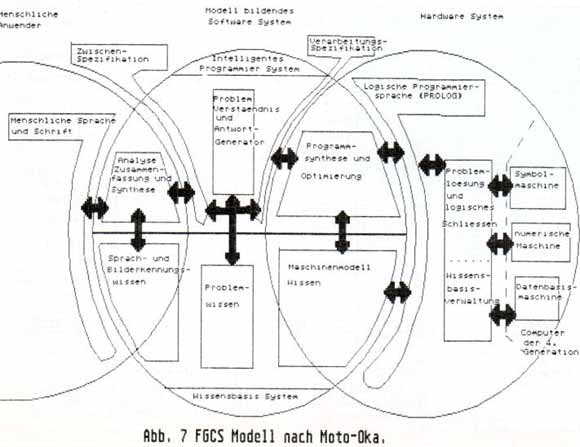
Um die anfallende Datenflut zu bewältigen, sollen parallel arbeitende Computer in einem System zusammengefaßt werden. Parallele Datenverarbeitung setzt aber nebeneffektfreie Sprachen voraus, wie sie z. B. in den eingangs erwähnten, applikativen Sprachen vorliegen. Im FCGS (Fifth Generation Computer System) Report wird namentlich PROLOG erwähnt. So wird man also bei der Durchschlagskraft der Japaner auf dem Computergebiet damit rechnen müssen, daß Prolog in der Zukunft erheblich an Bedeutung zunehmen wird. Und wie soll er aussehen, der Supercomputer der 5. Generation, der nun wirklich intelligent sein soll? Abb. 7 zeigt die aus [14] entnommene Skizze. Eine Problemlösungsmaschine steuert die Symbole verarbeitenden und numerische Berechnungen durchführenden Computer der 4. Generation. Diese ist gekoppelt mit einer Maschine, welche die Datenbasis verwaltet. Diese Maschine wird in einer logischen Programmiersprache programmiert, die von einem übergeordneten Softwaresystem gesteuert wird. Dieses System soll die Verwaltung der Heuristiken sowie die Auswertung des menschlichen Peripherieinterfaces (also Sprache verstehen, Bilder erkennen etc.) übernehmen. Ganz links dann der Mensch, der seine Aufgabenstellung nahezu in Umgangssprache formulieren darf.
Die obligatorische kritische Schlußbemerkung
Natürlich gibt es Leute, die der sich abzeichnenden Entwicklung skeptisch gegenüberstehen. Die Menge dieser Kritiker läßt sich wohl in drei Teilmengen sortieren.
- Menge aller Personen die gegen Computer generell sind, (reden wir nicht darüber, es hat auch Leute gegeben, die gegen die Benutzung der Eisenbahn etc. gewettert haben).
- Menge der Personen, die den Einsatz von Computern (besonders von intelligenten) kritisch reflektiert wissen möchten. J. Weizenbaum [17] ist ein solcher prominenter Vertreter, und er warnt sicher zu Recht vor der Computerhörigkeit, der vor allem Menschen ohne tiefgehende Kenntnis des Computers erliegen.
- Menge der Personen, die anzweifeln, daß es jemals gelingen wird, wirklich intelligente Computer zu bauen. H. Dreyfus [6] gehört in diese Menge. Nun, wir sollten es zumindest versuchen.
Jedenfalls finde ich es symptomatisch, daß die letzten beiden Bücher in deutscher Übersetzung existieren, eines der Hauptwerke der KI (P. H. Winston. [20]) jedoch nicht.
Dr. Sarnow
[1] Barr, Avron und Edward Feigenbaum. The Handbook of Artificial Intelligence (Vol. 1-3). Heuristech Press. Stanford, 1981.
[2] Brooks, R. A. Symbolic Reasoning among 3-D Models and 2-D Images. Artifical Intelligence, vol 17. August 1981.
[3] Buchanan, Bruce G. and Edward H. Shortliffe. Rule-Based Expert Programs: the MYCIN Experiments of the Stanford Heuristic Programming Project. Addisob Wesley. Reading MA. 1984.
[4] Colmerauer, Alain, H. Kanoui, R. Pasero und P. Roussel. Un Systeme de Communication Homme-Machine en Franjais. Internal Report. Groupe d’Intelligence Artificielle. Universite Aix-Marseille II. 1973.
[5] Cuadrado, J. L. und Clara Cuadrado. AI in Computer Vision. BYTE, Jan. 1986, p. 237.
[6] Dreyfus, Huben. What Computers Can’t do. New York 1972
[7] Forschungsführer Künstliche Intelligenz. Gesellschaft für Informatik. 5300 Bonn.
[8] Hamann, C. M. Einführung in das Programmieren in LISP. Walter de Gruyter. Berlin 1985.
[9] Hawker, J. Scott, R. N. Nagel, Richard Roberts and Nicholas G. Odrey. Multiple Robotic Manipulators. BYTE Jan 1986.
[10] Iyengar, S. S., C. C. Jorgensen, S. V. N. Rao und C. R. Weisbein. Robot Navigation Algorithms using Learned Spatial Graphs. ORNC technical report ORNC-TM-9782. August 8, 1985.
[11] Jorgensen, Charles, William Hamei und Charles Weisbin. Autonomus Robot Navigation. BYTE Jan. 86. p. 223.
[12] Lenat, Douglas, B. Software für künstliche Intelligenz. Spektrum der Wissenschaft. Sonderheft Computersoftware. 1985.
[13] Lindsay, Robert, Bruce G. Buchanan, Edward A. Feigenbaum and Joshua Lederberg. Applications of Artificial Intelligence for Chemical Inference: The DENDRAL Projekt. McGraw-Hill Book Company. New York 1980.
[14] Moto-Oka, T. Fifth Generation Computer System. Elsevier. New York 1982.
[15] Robinson, J. A. The Generalized Resolution Principle. in Machine Intelligence 3. ed. Donald Michie. Elsevier. New York 1968.
[16] Steinbuch, Karl. Die informierte Gesellschaft. S. 293. dva. Stuttgart, 1966.
[17] Weizenbaum, Joseph. Die Macht der Computer und die Ohnmacht der Vernunft. Frankfurt 1977.
[18] Winograd, Terry. Understanding Natural Language. New York 1972.
[19] Winograd, Terry. Software für Sprachverarbeitung. Spektrum der Wissenschaft. Sonderheft Computer Software 1985.
[20] Winston, Patrick. Artificial Intelligence. Reading Mass. 1984.