Probleme aus dem Bereich der künstlichen Intelligenz wurden bisher stets in LISP programmiert. Einen Überblick über mögliche Anwendungsprobleme lieferten wir in der November-Ausgabe dieser Zeitschrift. Für den ST-Programmierer steht nun eine LISP-Version in der „Public-Domain Software“ (Disk Nr. 7) zur Verfügung.
Woher kommt XLISP?
XLISP von David Michael Betz ist wohl die älteste Public-Domain-Version von LISP. Der Interpreter ist in C geschrieben. Da der Source Code mitgeliefert wird, läuft dieser Interpreter auf allen bekannten Computern, für die ein C-Compiler lieferbar ist. Koordinator des Projektes ist der Autor selbst, der als „Senior Editor“ der angesehenen amerikanischen Zeitschrift BYTE die Entwicklung der verschiedenen Versionen in der Hand behalten möchte. Der Source Code fehlt zwar auf der PD-Diskette der ST-Computer-Redaktion, ist jedoch direkt beim Autor zu beziehen; die Adresse findet sich in der PD-Dokumentation. Ich habe außerdem zehn Dollar für die Deckung der Versandkosten beigefügt.).
XLISP steht für eXperimental LISP. Entsprechend vielzählig sind die verfügbaren Versionen. Auf der PD-Disk Nr. 7 finden sich die Versionen 1.4 und 1.5. Auf meine Anfrage nach dem Source Code wurde mir jedoch gleich die Version 1.7 zugeschickt. Die Versionen 1.4 und 1.5 unterscheiden sich durch die Einbindung von Gleitkomma-Routinen in die Version 1.5 sowie die Änderung der Routinen für die objektorientierte Programmierung. Ab Version 1.5 unterscheidet der Interpreter Groß- und Kleinschreibung nicht mehr.
In der Version 1.5 steckt außerdem noch ein ohne Source Code nicht näher lokalisierbarer Fehler: Beim Laden des Prolog Interpreters ”Prolog.LSP”. Die Version 1.7 ist nun fast fehlerfrei. Allerdings gelingt es in dieser Version nicht, Objekte und Klassen zu definieren, da die newvector-Routine, die neuen Speicherplatz für die Objectvectoren bereit stellt, nicht richtig arbeitet. Dieser Fehler ist von mir inzwischen behoben worden: XLISP steht damit als Version 1.71 zur Verfügung. Wir beschreiben diese Version, in der wir bisher keinen Fehler entdeckt haben.
Eigenschaften
Die Dokumentation besteht aus einem 43-seitigen File auf der Diskette. Jede Version enthält leichte Änderungen. Der Autor möchte die Versionen im Laufe der Zeit immer mehr dem Common Lisp Standard anzugleichen. Aus dem Umfang der Dokumentation geht schon hervor, daß David Betz sie eher als „Quick Reference“, als schnelle Informationsquelle verstanden wissen möchte. Für Anfänger empfiehlt sich daher unbedingt die Benutzung eines Lehrbuches. Wegen der inzwischen erreichten starken Kompatibilität zu Common Lisp ist das Lehrbuch von Winston und Horn [2] hervorragend geeignet, falls man vor der Sprachbarriere (das Buch ist in Englisch geschrieben) nicht zurückschreckt. Unter der deutschen Literatur ist für Anfänger am ehesten das Werk von Hamann [1] für Anfänger zu empfehlen. Nur für die objektorientierte Programmierung sollte man neuere Literatur hinzuziehen, da XLISP hier gegenüber [Hamann] deutlich abweicht und dem Konzept von Smalltalk nähergerückt ist. Aber dieses Kapitel muß man als Anfänger ja nicht sofort in Angriff nehmen.
Zum Starten des Programms sollte man sich unbedingt ein Menü schreiben oder ein User Shell verwenden. Ich habe das MENU + Programm aus dem Lattice C Compiler zusammen mit einer 500 kByte RAM-Disk aus der PD installiert. Alle Programme können dann durch Anklicken aus dem MENU+ Menü aufgerufen und editiert werden. Man muß lediglich das File ”MENU.INF” entsprechend Abb. 1 mit Hilfe des Editors abändern. Ein Editor ist übrigens dringend erforderlich, weil das Erstellen und Abspeichern von Funktionen direkt im Interpreter Mode von XLISP zumindest mühsam ist. Und durch die Verwendung der RAM-Disk erhält man fast schon TURBO-Komfort. Das Programm MENU + ist sowohl im Pascal Compiler von Metacomco enthalten als auch einzeln erhältlich. Wenn es noch nicht geschehen ist, sollte XLISP als TTP-Programm vereinbart werden.
Dann nämlich werden alle in der Parameter Box angegebenen Programme beim Start automatisch geladen (.LSP wird automatisch hinzugefügt!). In Abb. 1 werden stets die Programme PP.LSP und TRACE.LSP geladen. Diese Programme sind beim Austesten von LISP-Programmen sehr hilfreich und befinden sich auf der PD-Disk Nr. 7. "PP.LSP” bringt ein pretty print (also ein gut gegliedertes Listing) einer Funktion auf den Bildschirm oder ein sonstiges Ausgabegerät. "TRACE.LSP” ermöglicht es, den Aufruf von Funktionen zu verfolgen. Soll etwa die Funktion TEST ausgedruckt werden, so geschieht das mit (PP TEST). Das Einschalten des TRACE-Modus für diese Funktion erfolgt dagegen durch (TRACE TEST). Vergißt man das Hochkomma, so wird nicht die Funktion, sondern der evaluierte Wert der Funktion in die TRACE-Liste aufgenommen. Mit (UNTRACE TEST) wird die Funktion aus der TRACE-Liste wieder herausgenommen. Man sollte sich übrigens wirklich die Mühe machen, die Beispielprogramme genau zu studieren. Man kann von ihnen viel über die Besonderheiten, etwa die Verwendung optionaler Parameter, lernen. So kann beispielsweise die PP-Funk-tion das Listing auch auf einem Drucker oder File ausgeben. Es muß dann zunächst ein File eröffnet werden, und zwar auf ähnliche Weise wie in C mit (SETQ DRUCKER (OPENO "lst:")), wenn der Drucker zur Ausgabe eröffnet werden soll. Anschließend kann PP veranlaßt werden, den Ausdruck auf den Drucker zu leiten, indem DRUCKER als optionaler Parameter angegeben wird (z. B.: (PP TEST DRUCKER)). (CLOSE DRUCKER) schließt den File wieder. Auf die gleiche Weise können auch Files auf Diskette zum Lesen und Schreiben geöffnet werden.
Tabelle 1 faßt die in XLISP verfügbaren Funktionen zusammen. Darin sind die Funktionen, die in COMMON LISP nicht verfügbar sind, fett gedruckt. Bei diesen Funktionen handelt es sich meist um solche, die leicht in C zu programmieren sind und den iterativen Programmierstil unterstützen. Die Freunde puren LISPs werden hierüber die Nase rümpfen, aber manchmal können diese Funktionen ganz praktisch sein. Systemfunktionen, die in XLISP anders implementiert sind als in COMMON LISP oder dort nicht benötigt werden, sind hell gedruckt. Die Unterschiede sind zumeist von untergeordneter Bedeutung.
#############################################
# #
# Standard C MENU+ info file #
# #
# Copyright (c) 1986 Metacomco plc #
# #
#############################################
#
# Tools menu item definitions
#
# Form: <item name> = Ccommand line definition>
#
TOOLS
EDIT = {command_dir}\ED.TTP {path}\{file}.{type} {editor_opts}
LISP = {command_dir}\XLISP.TTP {compiler_opts} {path}\{file}.{type}
#
# File menu item definitions
#
# Form: <item name> = <file pattern>
#
FILE
Choose = *.*
Choose LSP = *.LSP
#
# Option menu item definitions
#
# Form: <option name> = <initial value>
#
OPTIONS
CURRENT_DIR = C:
PATH = C:
COMMAND_DIR = C:
EDITOR_OPTS =
COMPILER_OPTS = PP TRACE
Abb. 1: Das File MENU +
**Tabelle 2:** COMMON LISP Funktionen, die nicht in XLISP Version 1.7 aufgeführt sind.
(adjoin), (array-dimension), (ash), (atan), (defstruct), (first), (format), (ged), (intersection), (isqrt), (logtest), (mapean), (merge), (pairlis), (proclaim), (psetq), (remove-duplicates), (remove-if), (remove-if-not), (rest), (round), (second), (set-difference), (sort), (special), (step), (symbol-function), (trace), (union), (unless), (when), (y-or-n-p).
**Tabelle 3:** Datentypen in Xlisp
Integer, Float, Strings, Objekte, Felder, Symbole, Filepointer, Unterprogramme (eingebaute) und E/A-Ströme.
Tabelle 1: LISP Funktionen in XLISP 1.7
Funktionen, die von COMMON LISP abweichen, sind kursiv gedruckt. Solche, die in XLISP, aber nicht in COMMON LISP Vorkommen, sind fett gedruckt.
Evaluationsfunktionen:
(eval), (apply), (funcall), (quote), (function), (backquote), (lambda).
Symbolfunktionen:
(set), (setq), (setf), (defun), (defmacro), (gensym), (intern), (make-symbol), (symbol-name), (symbol-value), (symbol-plist), (hash).
Property Listen Funktionen:
(get), (putprop), (remprop).
Array Funktionen:
(aret), (make-array).
Listenfunktionen:
(car), (cdr), (cxxr), (cxxxr), (cxxxxr), (cons), (list), (append), (reverse), (last), (member), (assoc), (remove), (length), (nth), (nthcdr), (mapc), (mapcar), (mapl), (maplist), (subst), (sublis).
Destruktive Listenfunktionen:
(rplaca), (rplacd), (nconc), (delete).
Prädikatsfunktionen:
(atom), (symbolp), (numberp), (null), (not), (listp), (consp), (boundp), (minusp), (zerop), (plusp), (evenp), (oddp), (eq), (eql), (equal).
Kontrollstrukturen:
(cond), (and), (or), (if), (case), (let), (let*), (catch), (throw).
Schleifenstrukturen:
(do), (do*), (dolist), (dotimes).
Programmeigenschaften:
(prog), (prog)*, (go), (return), (prog1), (prog2), (progn).
Debugging und Fehlerbehandlung:
(error), (cerror), (break), (clean-up) (top-level), (continue), (errset), (backtrace), (evalhook).
Arithmetische Funktionen:
(truncate), (float), (+ ), (-), (*), (/), (1+ ), (1-), (rem), (min), (max), (abs), (random), (sin), (cos), (tan), (expt), (exp), (sqrt).
Bitweise logische Funktionen:
(logand), (logior), (logxor), (lognot).
Relationsprädikate:
(<), (<=), (=), (/=), (>=), (>)
String Funktionen:
(char), (String), (strcat), (substr).
Ein/Ausgabe Funktionen:
(read), (print), (prinl), (princ), (terpri), (flatsize), (flatc).
File E/A Funktionen:
(openi), (openo), (close), (read-char), (peek-char), (write-char), (read-line).
Systemfunktionen:
(load), (transcript), (gc), (expand), (alloc), (mem), (type-of), (peek), (poke), (address-of), exit).
Tabelle 2 zeigt die Funktionen, die zwar unter COMMON LISP, nicht aber unter XLISP verfügbar sind. Einige dieser Funktionen sind aber bereits auf der PD-Disk Nr. 7 als Lisp-Programme vorhanden (z. B. ”TRACE.LSP”).
Tabelle 3 faßt die in XLISP 1.7 vorhandenen Datenstrukturen zusammen. Wie man sieht, muß XLISP 1.7 den Vergleich mit teureren LISP Versionen nicht scheuen. Allerdings sind einige der Datenstrukturen in Version 1.7 brandneu hinzugekommen. Ein Beispiel ist der Datentyp Array. Eigentlich erübrigt sich wohl so etwas wie ein Benchmark-Test (einem geschenkten Barsch...), aber um eine Idee von der Leistungsfähigkeit von XLISP zu bekommen, habe ich ein rekursives Quicksort-Programm geschrieben, das ich in Bezug zu den entsprechenden Zeiten der BASIC- (iteratives Quicksort), Logo- (eingebauter Sort Befehl) und C-Version, gesetzt habe (Tabelle 4). Dabei ergab sich für 100 Elemente ein Stack Overflow Error für die rekursive Quicksort Routine in XLISP. Das muß mit einem Bug in der Stack Verwaltung Zusammenhängen, denn einen 1 MByte Rechner sollte ein 100 Element-Quicksort-Program m nicht aus dem Sattel werfen. Für diese Vermutung spricht auch eine String-Fehlermeldung, falls man den zur Verfügung stehenden Speicherplatz mittels expand zu stark erweitert. Ich habe deshalb das in der PD-Disk Nr. 7 befindliche Sortierprogramm durch direktes Einfügen ebenfalls benutzt. Da es weniger verschwenderisch mit dem Stack umgeht, läuft die Sortierroutine (allerdings in schneckenhaftem Tempo).
Nun ja, LISP ist eben keine Compilersprache für gewöhnliche Arithmetik.
Ein großer Vorteil von XLISP ist aber die Möglichkeit, objektorientiert zu programmieren. Man kann sich dabei in einer SMALLTALK-ähnlichen Syntax versuchen. Da dieses Kapitel auch in keinem der genannten LISP-Lehr-bücher in ähnlicher Weise behandelt wird, möchte ich kurz die Grundlagen unter Verwendung der XLISP-Syntax erörtern.
Objektorientierte Programmierung in XLISP
In normalen Programmiersprachen wirkt eine aktive Prozedur oder Funktion auf die passiven Daten ein. Anders in objektorientierten Sprachen. Hier ist das Objekt (Daten) zentrales Element. Will man, daß eine bestimmte Operation durchgeführt wird, übermittelt man dem Objekt eine Mitteilung, worauf die gewünschte Operation mit einer geeigneten Methode ausgeführt wird. Bei der Definition der Datenstrukturen (Objekte) wird eine strenge Hierarchie beachtet. Abb. 2 zeigt diese Hierarchie. Die Klasse enthält alle nötigen Informationen, um die Instanzen (engl.: Instance) zu benutzen und zu konstruieren. Die Instanzen einer Klasse sind dann die Datenstrukturen (Objekte), die die Daten (z. B. Zahlen) enthalten, mit denen wir arbeiten wollen. Jede Instanz gehört zu einer Klasse. Jede Klasse besitzt mehrere Instanzen. Jede Klasse erbt alle Eigenschaften der übergeordneten Superklasse. Jede Instanz einer Klasse natürlich auch. Um ein anschauliches Beispiel zu geben, habe ich das Programm Differentiate aus [2] in objektorientierte Schreibweise umgesetzt (Listing 1). Die ersten drei Funktionen dienen lediglich der besseren Lesbarkeit. Da die Funktionsterme in LISP-Notation eingegeben werden müssen (selbstverständlich gibt es Programme, die von der uns gewohnten Infix-Notation in die LISP-Notation (Präfix) umwandeln, aber immer sachte...), ist der car der Liste immer der Operator. Arg1 und Arg2 sind das erste und zweite Argument der Funktionsliste und stellen somit die zu verknüpfenden Funktionsterme dar. Als nächstes wird dann die Klasse Regeln erzeugt. Diese erbt alle Eigenschaften der obersten aller Klasse mit dem Namen Object. Dann wird die Instanz Ableitungsregel als Instanz der Klasse Regeln erzeugt. Diese Instanz ist nun in der Lage unsere Nachrichten und Methoden zu speichern, während die Klasse Regeln lediglich eine Schablone für die Instanz darstellt. Nun werden die Nachrichten für die Instanz Ableitungsregel der Klasse Regeln definiert. Es handelt sich bei den Nachrichten lediglich um die Operatoren, welche die verschiedenen Methoden auslösen. Das ist wie im richtigen Leben: durch + verknüpfte Terme werden mit Hilfe der Summenregel abgeleitet etc. Die Nachrichten sind in einer sogenannten Property-Liste abgelegt, deren Suchschlüssel der Operator und deren Wert die zugehörige Nachricht ist.
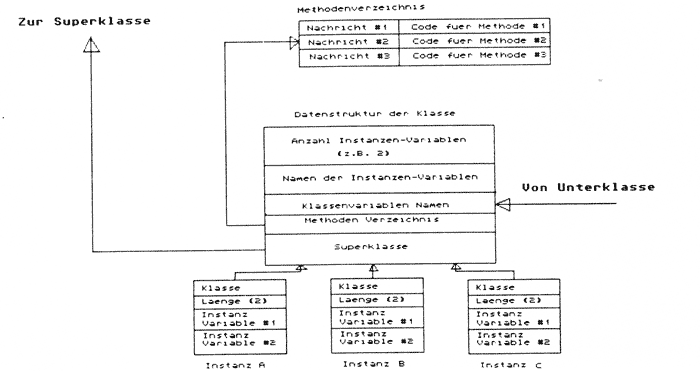 Abb. 2: Hierarchie von Objekten (nach [3])
Abb. 2: Hierarchie von Objekten (nach [3])
| Anzahl Elemente |
BASIC |
C |
LOGO |
XLISP Einfügen |
XLISP Quicksort |
| 50 |
- |
- |
- |
8 |
5 |
| 100 |
6 |
0,03 |
3 |
20 |
- |
Tabelle 4: Rechenzeiten der Quicksort Routine (in Sekunden):
Aus dieser Property-Liste (opmessages) wird dann die Operatornachricht zusammen mit der Funktion f und der Ableitungsvariablen x an die Instanz Ableitungsregel der Klasse Regeln übergeben, um im Hauptprogramm die Ableitung vorzunehmen. Es sieht zwar aus, als ob die Ableitungsfunktion nicht rekursiv wäre, aber in den einzelnen Methoden kömmt natürlich wieder die Ableitung vor, sodaß die Lösung auch rekursiv abläuft. Als letztes werden die einzelnen Methoden für die verschiedenen Nachrichten an das Objekt Regeln definiert.
;Listing 1.
;Objektorientierte Ableitung von Funktionen.
;Die Funktionen müssen in LISP Notation eingegeben werden.
;Beispiel f(x)=3x^2 als (* 3 (potenz x 2))
;Der Aufruf für die Ableitung dieser Funktion lautet dann:
;(ableitung '(* 3 (potenz x 2)) 'x)
(defun operator (list) (car list!)
(defun arg1 (list) (cadr list))
(defun arg2 (list) (caddr list))
;Definiere die Klasse "Regeln".
(setq regeln (class :new '()))
;Erzeuge eine neue Instanz der Klasse "Regeln".
(setq ableitregel (regeln :new))
;Definiere die Nachrichten für die Operatoren und lege sie
;in der Property-Liste "opmessages" ab.
(putprop 'opnessages ':+ '+)
(putprop 'opmessages ':- '-)
(putprop 'opmessages ':* '*)
(putprop 'opmessages ':/ '/)
(putprop 'opmessages ':potenz 'potenz)
;Das eigentliche LISP Programm zur Ableitung einer Funktion f.
;f ist die Funktion, x ist die Ableitungsvariable
(defun ableitung (f x)
(cond ((atom f) (cond ((equal f x) 1)
(t 0) ) )
(t (ableitregel (get 'opmessages (operator f)) f x)))
;und nun die einzelnen Regeln:
;Summenregel
(regeln :answer :+ '(f x)
' ((+ (ableitung (arg1 f) x) (ableitung (arg2 f) x))))
;Differenzregel
(regeln :answer :- '(f x)
' ((- (ableitung (arg1 f) x) (ableitung (arg2 f) x))))
: Produktregel
(regeln :answer :* '(f x)
'('(+ (* ,(arg1 f) ,(ableitung (arg2 f) x))
(* ,(arg2 f) ,(ableitung (arg1 f) x)))))
;Quotientenrege1
(regeln :answer :/ '(f x)
'('(/ (- (* ,(ableitung (arg1 f) x) ,(arg2 f))
(* ,(arg1 f) ,(ableitung (arg2 f) x)))
(* ,(arg2 f) ,(arg2 f)))))
; Potenzregel
(regeln :answer :potenz '(f x)
'('(* ,(arg2 f) (* (potenz ,(argl f) ,(- (arg2 f) 1))
,(ableitung (arg1 f) x)))))
Starthilfe für XLISP-Anfänger
Um LISP-Anfängern den Einstieg zu erleichtern, hier die ersten Hinweise wie XLISP zu starten ist und was der LISP-Interpreter eigentlich macht. Die ersten Schritte in XLISP unternimmt man am besten im direkten Interpretermodus. XLISP ist als Interpretersprache den meisten BASIC Anwendern von der Arbeitsweise vertraut. Man gibt einen Befehl ein und erhält Die Schreibweise ist etwas ungewohnt, denn jeder LISP-Befehl ist in runde Klammern einzuschließen. Um das System zu starten, klicken wir ”XLISP. TTP” an. In der Dialogbox geben wir ”PP” und ”TRACE” an. XLISP startet nun und zeigt die Copyright-Mitteilung. Dann lädt das Programm ”PP. LSP” und "TRACE.LSP”. Mit diesen beiden Funktionen haben wir die oben erwähnten Utilities stets griffbereit. Danach zeigt der Interpreter mit ” > ” an, daß er bereit ist, LISP Funktionen zu evaluieren (d. h. den Wert der Variablen X auszugeben). Tippt man (X) ein, antwortet der Interpreter mit der Fehlermeldung "Unbound Variable”. Logisch: Der Interpreter versucht den Wert der Variablen X zu bestimmen und erkennt, daß diese noch nicht an einen Wert gebunden wurde. Weist man der Variablen mit (SETQ X 3) den Wert 3 zu, dann ergibt dieselbe Eingabe (X) die Antwort 3. Wegen der Eigenschaft, nach der Eingabe sofort den Wert der Funktion oder der Variablen zu ermitteln, zählt XLISP zu den EVALLISP-Interpretern. Die Evaluierung kann auch unterbunden werden mit der Funktion QUOTE, abgekürzt Die Anweisung (’X) gibt die Antwort X, weil durch ’ die Evaluierung unterbunden wurde. Da wir schon bei den Variablen sind: LISP kennt als Datenstrukturen eigentlich nur „Atome“ (nicht weiter zerlegbare Datenstrukturen) und „Listen“ (von ihnen hat LISP seinen Namen: LISt Processing). Man kann sich Atome in Lisp als wortähnliche und Listen als satzähnliche Gebilde vorstellen. Atome und Listen werden gemeinsam symbolische Ausdrücke (engl.: symbo-lic Expressions: SEXPR) genannt. Das obige kleine Beispiel zeigt schon die Fähigkeit von LISP, mit Symbolen umzugehen. Schauen wir uns zunächst einige Lisp-Atome an: Alle Zahlen sind Lisp-Atome (numerische Atome). Bei der Bearbeitung dieser Atome wählt Lisp die Präfix Notation, d. h. die zu bearbeitenden numerischen Atome (Zahlen) werden zusammen mit einem vorgezogenen Operatorsymbol (einem symbolischen Atom) in einer Liste zusammengefaßt. Zum Beispiel ergibt die Eingabe (+2 6) das Ergebnis 8 auf dem Bildschirm. Die einzelnen zu bearbeitenden Symbole (das symbolische Atom und die beiden numerischen Atome) wurden hierzu in runden Klammern geschrieben und damit zu einer Liste zusammengefaßt. Und was ergibt (+2 X)? Falls Sie das erste Beispiel eingetippt haben, natürlich 5. Klar?
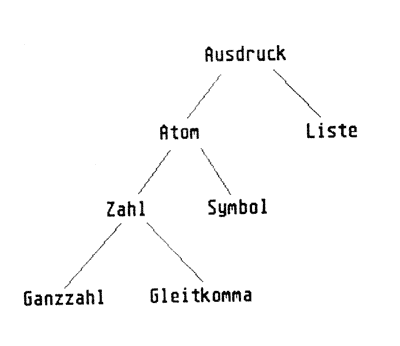 Abb. 3: Hierarchie der Datenstrukturen in LISP
Abb. 3: Hierarchie der Datenstrukturen in LISP
Richtig, das symbolische Atom (kurz: Symbol) X wurde mit setq an das numerische Atom 3 gebunden. Eine Liste besteht also aus einer linken sich öffnenden Klammer gefolgt von 0 oder mehr Atomen oder Listen, gefolgt von einer rechten sich schließenden Klammer. Die Liste 6+ (* 2 3) (/ 1 2)) ist also nichts anders als die Präfix-Schreibweise des einfachen algebraischen Terms ((2 * 3) + (1/2)), welcher den Wert 6.5 besitzt. Die Hierarchie der verschiedenen Datentypen in LISP zeigt Abb. 2. Dieses Diagramm gilt für XLISP erst von der Version 1.5 an, da bis dahin die Gleitkommazahlen fehlen. Aber für numerische Rechnungen allein ist ein LISP-Interpreter ohnehin zu schade. Das erledigen die altbekannten PASCAL- oder C-Compiler schneller und (da XLISP in C geschrieben wurde) mit gleicher Genauigkeit (siehe obigen "Benchmark”-Test).
Schwerpunkt von LISP ist, wie der Name sagt, die Listen Verarbeitung. Deshalb schauen wir uns in dieser kurzen Einführung wenigstens noch die wichtigsten Funktionen zur Listenverarbeitung an. Diese sind CAR und CDR (sprich kaar und kjuudr). Die Bezeichnung beider Funktionen ist rein historisch und hat keinen symbolischen Wert mehr. Man übersetzt die Funktionen wohl am besten mit ERSTES und REST. CAR liefert nämlich das erste Objekt (Atom oder Liste) einer Liste, während CDR eine Liste zurückgibt, in der alle Objekte der Ausgangsliste enthalten sind, bis auf das erste. Nehmen wir folgendes Beispiel: Wir wollen CAR und CDR der Liste (A B C) erhalten. Dazu geben wir ein (CAR ’(A B C)) und erhalten A. Nach (CDR ’ (A B C)) erfolgt die Ausgabe (BC).
Beachten Sie das Hochkomma vor (A B C). Seine Bedeutung wird klarer, wenn man zunächst das Atom LISTE an die Liste (A B C) bindet: (SETQ LISTE ’(A B C)). (CAR LISTE) (ohne Hochkomma) liefert jetzt den gleichen Wert (nämlich A), weil LISP zunächst den Wert von LISTE evaluiert, (A B C) erhält und davon den CAR ermittelt. In (CAR (A B C)) würde LISP auch versuchen, den Wert von (A B C) zu evaluieren. Mangels Bindung würde LISP jetzt allerdings einen Fehler melden. Das Hochkomma stoppt also die Evaluierung und übernimmt den nachfolgenden Ausdruck unevaluiert. (CAR 'LISTE) würde ebenfalls zu einem Fehler führen, weil LISTE unevaluiert ein Atom und keine Liste ist. Diese essentiellen LISP-Befehle sind in XLISP identisch mit der in [2] gegebenen Nomenklatur. Abb. 3 zeigt nochmal den Evaluierungsprozeß in der Übersicht.
Natürlich reicht hier der Platz für eine ausführliche Einführung in LISP mit Hilfe des XLISP-Systems nicht aus. Ich hoffe jedoch, daß der ungeübte Benutzer in die Lage versetzt wurde, XLISP zu starten und anhand eines der aufgeführten Lehrbücher tiefer in diese großartige Symbolmanipulationssprache einzudringen. Es lohnt sich in jedem Fall, das XLISP System aus der PD zu besorgen und die einschlägigen Lehrbücher und mitgelieferten Beispielprogramme durchzuarbeiten.
Kleines Lexikon für objektorientierte Programmierung in XLISP
Instanz
Hier wird die im Objekt Klasse definierte Datenstruktur realisiert, und die aktuellen Werte der Instanz-Variablen werden abgelegt. Alle Instanzen einer Klasse haben die gleiche (in der Klasse festgelegte) Datenstruktur.
Instanzen-Variable
Private Datenstruktur, die nur dem Objekt und seinen Methoden zugänglich ist. Hier werden Informationen über die verschiedenen Instanzen der gleichen Klasse gespeichert.
Klasse
Datenstruktur, die die Informationen für alle gleichartigen Objekte enthält. Siehe Abb. 4.
Methode
Lisp-Programm, das auf eine Nachricht hin aktiviert wird und nur für ein bestimmtes Objekt definiert ist.
Nachricht
Sie veranlaßt ein Objekt, den vorher definierten Code auszuführen.
Objekt
Zentrale Datenstruktur, die Speicherplätze für private Informationen und einen Satz von Methoden enthält.
Literaturangabe:**
[1] Hamann, C. M. Einführung in das Programmieren in LISP. Walter de Gruyter. Berlin 1982.
[2] Winston, Patrick Henry und Berthold Klaus Paul Horn. LISP. Second Edition. Addison Wesley. Reading 1984.
[3] Pascoe, Geoffrey A. Elements of Object-Oriented Programming. BYTE August 1986. p. 139 ff.
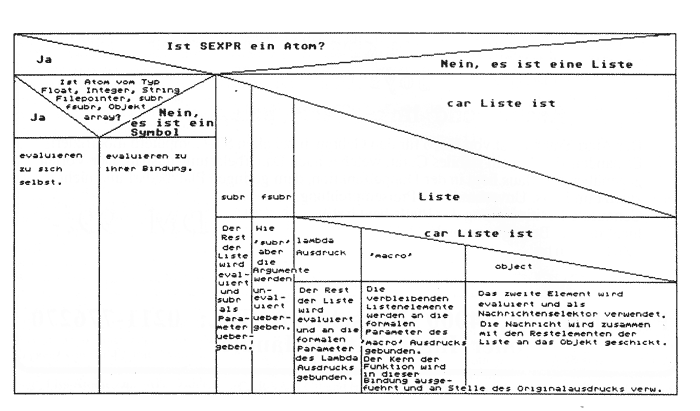 Abb. 4: Struktogramm des Evaluationsprozesses
Abb. 4: Struktogramm des Evaluationsprozesses