
Migraph OCR: Wenn Pixel-Mischmasch zu Buchstaben wird

Man stelle sich vor: Es wird ein Schriftstück in ein Lesegerät gegeben, und kurz darauf steht der Text in einer EDV-Anlage zur elektronischen Weiterverarbeitung bereit. Was wir Menschen schon intuitiv verrichten, irgendwelche Textzeilen zu lesen, das ist für den Computer reine Schwerstarbeit. Das Erkennen von Schriftzeichen (engl. 'character') durch eine EDV-Anlage wurde erst durch schnelle Prozessoren und ausgefeilte Programmiertechnik möglich.
OCR, wie diese relativ neue Disziplin auf dem Computer genannt wird, kommt von ‘Optical Character Recognition', was zu deutsch exakt ‘optische Zeichenerkennung’ heißt. Oftmals wird der selbe Sachverhalt mit ‘Texterkennung' oder ‘Schrifterkennung’ umschrieben.
Was ist denn nun ‘Zeichenerkennung'?
Es geht im Grunde nur darum, irgendwelche Grafik, denn nichts anderes sind eingelesene Schriftstücke zunächst, in computerverarbeitbare Zeichen (engl. Characters) umzuwandeln. Daß es sich bei dieser ‘Grafik’ um Buchstaben und Texte handelt, kann der Computer zunächst noch nicht wissen. Durch ein spezielles Lesegerät (Scanner) oder per Videokamera und einen nachgeschalteten Digitalisierer (A/D-Wandler) werden Hell/Dunkel-Impulse analog abgetastet, digital in den Rechner transportiert und dort in sogenannte ASCIl-Zeichen umgewandelt. Diese versteht der Computer u.a. als Buchstaben und kann sie weiterverarbeiten. Gerade der Umwandlungsprozeß aber hat es in sich!
Hardware-Voraussetzungen
So lange bei der Analog/Digital-Wandlung im Scanner nur zwischen ganz hell (weiß) und ganz dunkel (schwarz) unterschieden werden soll, wäre das ganze Verfahren kaum der Rede wert. Da wird ein sogenannter Pendelwert vom Scanner berücksichtigt, der helleren Werten einfach weiß' (= logisch 1) und eher dunkleren Werten ‘schwarz’ (= logisch 0) zuordnet. Aber sobald mit mehreren Graustufen gearbeitet wird oder sogar zwischen Farbnuancen unterschieden werden soll, muß der Scanner schon einiges leisten. Für jede Farbinformation und jede Abstufung gibt es dann einen anderen Wert.
Die Auflösung: Die Anzahl der Lesepunkte einer Scanner-Matrix (auch ‘Scan-Zeile’ genannt) bestimmt die Genauigkeit des Lesevorganges. So waren bislang 200 dpi und 300 dpi recht grob, ‘dpi’ = ‘dots per inch’, zu deutsch: Bildpunkte pro Zoll. Gerade an den Grenzen zweier Buchstaben können dabei Verwaschungen, Überschläge oder Auslassungen auftreten. Das ist insbesondere dann der Fall, wenn diese Buchstaben genau auf der Grenze zweier Lesedioden lagen. Bei einem DIN-A4-Blatt lesen etwa 3500 solcher Dioden eine Scan-Zeile ein (nicht verwechseln mit einer Textzeile).
Die Vorlage: Wenn der Kontrast zwischen Papier und Schrift nicht sehr hoch ist, kann es beim Pendelwert oft zu ‘Entweder-Oder-Entscheidungen’ kommen und das für jeden Lesepunkt einzeln. Das kann sehr oft zu gegensätzlichen Deutungen führen. Eine Verbesserung erreicht man, wenn die Scanner-Helligkeit größer gewählt wurde.

Der Erkennungsvorgang
Gehen wir davon aus, der Scanner hat uns eine schöne Schwarzweißgrafik geliefert. Bevor nun ein recht komplizierter Programmteil an die Arbeit geht, werden markante Grafikteile herausgesucht. Ganz wichtig sind durchgehende Linien. Weiße Linien, die ‘unbeschadet’ horizontal den Text durchlaufen, werden automatisch als Zeilenzwischenräume (der sogenannte ‘Durchschuß’) erkannt. Einige Programme prüfen auch in vertikaler Richtung und schließen dabei auf Block- bzw. Spaltengrenzen. Dann werden schwarze Linien in beiderlei Richtung aufgespürt und unsichtbar gemacht. Dabei muß das Programm gewisse Toleranzen berücksichtigen. Vertikale Linien beispielsweise, die so groß sind wie der Abstand der Zeilenzwischenräume oder weniger, dürfen nicht unterdrückt werden, es könnten ja Buchstaben sein. Horizontale schwarze Linien dürfen in aller Regel unbedenklich getilgt werden.
Verschiedene Programme prüfen besonders bei schwarzen Linien die unmittelbare Nachbarschaft ab, um sicherzugehen, daß es sich wirklich um grafische Teile handelt. Durch diese Linienauslese werden insbesondere Bilder und Fotos ausgeschaltet. Einige Prüfroutinen stellen dabei sicher, daß nicht zufällig doch einige Buchstaben unter den Tisch fallen.
Verschiedene Vorgehensweisen der Software
Nun aber zum Erkennungsvorgang selber: Allen Verfahren liegt ein Gedanke zugrunde: Beim Einlesen über die Leuchtdiodenzeile des Scanners wird auf das Bild regelrecht ein Netz (‘Matrix’ genannt) gelegt. Dieses Netz legt sich in Teilen auch über jeden einzelnen Buchstaben, und innerhalb dieser Maschen kann ‘erkannt’ werden. Man kennt zur Zeit mindestens fünf verschiedene Verfahren, dem Zeichen auf den Buchstaben zu kommen.
Allereinfachst ist das Vergleichsprinzip (engl. Pattern Matching) bzw. der ‘ASCII-Vergleich’ (siehe auch Bild 1). Da muß vorher schon festgelegt sein, in welcher Schriftart und oftmals auch in welcher Größe der Text eingelesen wurde. In einer gewaltigen Bibliothek prüft das Programm die streng näherungsweise Ähnlichkeit und nimmt bei Eindeutigkeit der Suche einen Treffer an. So haben früher die allerersten Programme gearbeitet. Das Verfahren ist sehr unflexibel und nimmt keine Abweichungen hin, weshalb es heute immer seltener zum Einsatz kommt.
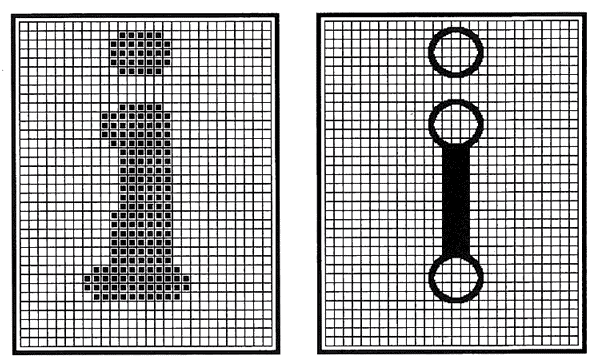
Etwas komplizierter wird die Suche nach den ‘markanten Punkten' (engl. Feature Points). So werden für einen bestimmten Buchstaben Punkte festgelegt, in denen er in höherem Maße ‘typisch ausgeprägt’ ist. Ausprägung heißt nichts anderes, als daß genau dort ein Kontrastunterschied, also eine gegenteilige Farbe, gegenüber den direkten Nachbarpunkten vorliegen muß.
Das Maß der Ausprägung bedeutet, daß in dem markanten Punkt ein Kontrastunterschied zu mehr als der Hälfte der Nachbarpunkte vorliegt. Je weniger unmittelbare Nachbarpunkte die selbe Farbe haben, desto höher das Maß der Ausprägung und desto markanter der Punkt. Nachbarpunkte sind auch jene Maschenquadrate, die nur mit einer Eckspitze an den fraglichen markanten Punkt stoßen, somit gibt es für einen Maschenpunkt immer 8 Nachbarn.
Typisches Beispiel hierzu: Das kleine ‘i’ (siehe auch Bild 2). Es hat mindestens drei markante Punkte, von denen der i-Punkt (im wahrsten Sinne des Wortes) der markanteste ist. Vom i-Punkt aus gesehen haben alle acht direkten Nachbarpunkte eine gegensätzliche Farbe, also hat dieser markante Punkt das höchstmögliche Maß an Ausprägung. Die Wahl der markanten Punkte unterliegt wichtigen Gesetzmäßigkeiten. So nimmt die Treffergenauigkeit ab, wenn zu wenige markante Punkte definiert wurden, kurioserweise ist das auch der Fall, wenn es zuviele sind. Auch sind die Lage, Entfernung und das Verhältnis der markanten Punkte zueinander zu beachten. Typische Punkte hoher Ausprägung sind End- und Eckpunkte. Punkte innerhalb von Linien eignen sich nicht als markante Punkte.
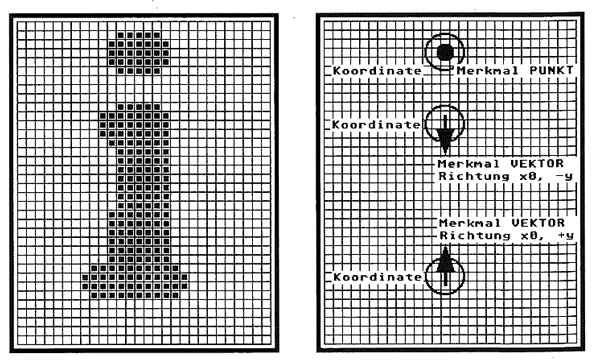
Ziemlich schnell hat man aus dem Prinzip der markanten Punkte das Drahtmodell (engl. Vector Model) entwickelt, aber nicht notwendigerweise, um dieses dadurch ablösen zu lassen. Dort wurde ganz einfach die Verbindung zwischen den Punkten sichtbar gemacht. Es genügt demgegenüber auch völlig, im markanten Punkt die Richtung des Linienverlaufes zu vermerken, also die Linie selbst nicht zu ziehen (siehe auch Bild 3). Vorteil dieser Verfeinerung: Es werden immer weniger markante Punkte zur Eindeutigkeit nötig.
Als Fortentwicklung dieses Modells zeigt sich das Einbeziehen typischer Muster (Feature Signs), wie Öffnungen auf bestimmten Seiten, bestimmte Winkelverhältnisse, Parallelitäten, Kreuzungen, Überlagerungen und ähnliches mehr.
Zwei Wege
Die Schrift(muster)erkennung ist in zwei Hauptrichtungen gespalten: Den vergleichenden Systemen einerseits ist eine mehr oder weniger große Bibliothek mit sogenannten Prototypen gemeinsam, über die dann der Vergleich stattfindet. Diese Programme zeichnen sich positiv durch hohe Treffsicherheit und zunächst auch hohe Geschwindigkeit aus, aber negativ durch hohen Arbeits- oder Massenspeicherbedarf. Je größer dann eine Bibliothek wird, um so langsamer ist der Erkennungsvorgang. Grenzen für einen tolerierbaren Zeitrahmen werden bald spürbar.
Andererseits gibt es typisierende Verfahren. Bei ihnen ist positiv der geringe Speicherplatz und eine fast immer hohe Geschwindigkeit zu werten. Negativ fällt die schwächere Treffsicherheit ins Gewicht. Das liegt hauptsächlich an der Kompliziertheit des benutzten Algorithmus.
Buchstabentypisches
Zur Zeit sieht der Trend in der Schriftmustererkennung danach aus, als würden die vergleichenden Programme an Bedeutung verlieren und die typisierenden schneller weiterentwickelt werden. Eine „Disziplin“, die derzeit im Kommen ist, nennt man Prinzip der typischen Muster'.
Bei den 'typischen Mustern' wird weniger ein bestimmter Linienverlauf oder ein Netz markanter Punkte benutzt (könnte natürlich zusätzlich der Fall sein), sondern vielmehr eine Merkmalsliste bestimmter Eigenschaften. Je typischer solche Merkmale für einen bestimmten Buchstaben sind, desto höher ist die Trefferquote. Es gibt sogar eine ausreichende Anzahl sogenannter 'ausschließlicher typischer Muster', die nur bei einem einzigen und keinem anderen Buchstaben sonst vorkommen. Auch ein Aufaddieren mehrerer solcher ausschließlichen Muster für einen Buchstaben ist denkbar, was die Trefferquote noch weiter erhöht.
Beispiele für typische Muster wären: Öffnungen auf bestimmten Seiten, Winkelverhältnisse, parallele Linien, Kreuzung von Linien, Überlagerungen von Merkmalen, geschlossene Kreise, Quadrate, Punkte und Zeichen und ähnliches mehr.
Hauptvorteil: Da die typischen Merkmale unabhängig von Schriftart, -große und -attributen immer gleich sind, führt dies auch bei technischen Unsicherheiten (z.B. schlechte Druckqualität, schräge Vorlage, schwankende Helligkeit usw.) fast immer zu einem sicheren Treffer. Wenn zudem mehr und mehr ausschließliche Muster definiert und erkannt werden können, steigt die Trefferquote fast proportional an. Dieses Verfahren ist extrem schnell, ihm liegt aber ein verhältnismäßig komplizierter Algorithmus zugrunde.
Der Duden liest mit
Aus den vergleichenden Programmen wird eine Weiterentwicklung in Verbindung mit einem eingebauten Wörterbuch versucht. Das Programm prüft nach Definition der Buchstaben ab. ob die gefundene Kombi nation mit der in einem Wörterbuch übereinstimmt. Ähnlich wie bei der Bibliothek der Prototypen, muß dann natürlich auch Arbeitsspeicher für dieses Wörterbuch vorhanden sein.
Solange die erkannten Wörter mit jenen im Lexikon übereinstimmen, läuft dieses Verfahren recht klaglos. Aber wenn unbekannte Wörter abgeprüft werden sollen, wird's kritisch. Da kann es bei mehreren ähnlichen, aber im Wörterbuch nicht vorhandenen Wörtern zum ‘Gleiche-Wörter-Konflikt' kommen. Wenn diese Gleichen-Wörter dann nur in einem Buchstaben variieren, muß der Mensch manuell die Entscheidung treffen, welches Wort richtig ist. Diese ‘Lexikonprogramme' arbeiten meistens so, daß zunächst alle Wörterbuch-Wörter erkannt werden und anschließend per Bildschirm oder Drucker eine Liste unbekannter Wörter ausgegeben wird. Ein Grundwortschatz von 30.000 bis 50.00 Wörtern ist akzeptabel, und daß sich das Wörterbuch automatisch erweitert, dürfte selbstverständlich sein.
Auch gibt es ein Problem mit Wörtern, die sich im Lexikon selbst nur durch einen einzigen Buchstaben unterscheiden. Was passiert, wenn just dieser eine Buchstabe falsch erkannt wurde? Dies hat schnell dazu geführt, daß außer dem Lexikon mit Wörtern auch noch ein Lexikon mit grammatikalischen und orthografischen Merkmalen mitgeführt wird. Auch wäre ein weiteres Lexikon undenkbarer Zeichenfolgen möglich. Z.B. drei Buchstaben hintereinander oder irre Folgen wie „grglhupf“, „sftwäre“ oder „Cmptr“. (Sie erkennen die Ähnlichkeit in der Denkweise mit den oben besprochenen typischen Mustern?)
Um es nun ganz auf die Spitze zu treiben, wäre sogar ein Lexikon mit dem typischen Satzbau denkbar (ist aber noch nicht realisiert worden). Vorteil der Lexikonprogramme: Unsicherheiten im Erkennungsprozeß können hiermit zusätzlich überwunden werden, außerdem können mehrere Lexikaprüfungen parallel ablaufen. Die Trefferrate im Erkennen ist sehr hoch. Es gibt aber (derzeit noch) einen Riesennachteil: der unermeßlich große Speicherbedarf und die hohe Rechenzeit. Deshalb werden auch Lexika vorerst nur zusätzlich angewandt.

Mit Mathematik erkennen
Als eines der jüngsten Kinder in der Familie darf man ‘rein mathematische Verfahren' zur Schrifterkennung begrüßen. Wohlgemerkt werden selbstverständlich in den vorher besprochenen Erkennverfahren auch mathematische Prinzipien angewandt, beispielsweise wenn es um Pendelwerte. Toleranzen oder Näherungen geht (diese sind aber hier nicht gemeint). Bei den ‘mathematisierten' Verfahren vielmehr ist an Statistik, Wahrscheinlichkeitsrechnung und Analysis gedacht.
Gleich das Hauptproblem vorweg: Diese mathematischen Prozesse können nicht für sich alleine arbeiten. Irgendein vorgeschaltetes Verfahren muß, in welcher Form auch immer. Anhaltspunkte bzw. Werte zum Erkennvorgang geliefert haben. Meist ist dies ein einfaches Raster wie bei dem Maskenvergleichsverfahren. Erst dann können komplizierte Algorithmen an die Arbeit gehen.
Die Entwicklung geht weiter - MIGRAPH OCR
Nach diesem kleinen Ausflug in die OCR-Theorie, dürfen wir Sie mit einem neuen Produkt für ATARI ST/TT bekannt machen, das der neueren Software-Entwicklung folgt. Zugegeben, es ist etwas still geworden um Texterkennungsprogramme rund um ATARI-Computer. Nachdem der Vorreiter auf diesem Gebiet, die Firma MARVIN AG, mit ihrer Tochterfirma TRILIAN AG (beide Schweiz) die Geschäftstätigkeit nahezu eingestellt hat, ist die Fortführung von SYNTAX bzw. AUGUR unsicher geworden. Auch ist das Programm SHERLOOK, früher von den beiden Entwicklern selbst vertrieben, in die Produktpalette von 3K eingegangen, und spektakuläre Updates sind nicht bekannt.
Deswegen darf die kleine Schar der OCR-Fans durchaus aufhorchen, daß uns nun ein reines US-Produkt auf dem deutschen Markt begegnet, das sich anschickt, gewissermaßen das Feld von hinten aufzurollen. Die altbekannten Programme aus deutschen, pardon: auch schweizer Landen, machen sich fast hauptsächlich vergleichende Prinzipien (Pattern Matching) beim Erkennungsvorgang zunutze. MIGRAPH OCR hingegen bedient sich fast ausschließlich unter anderem der neueren Technik der typischen Muster (Feature Signs), auch Omnifont-Prinzip genannt.
Vorkehrungen und Voraussetzungen
Unter der Prämisse, daß Sie der englischen Sprache mächtig sind, mindestens einen Handscanner der Fabrikate Migraph, Alpha Data oder Golden Image (oder irgend wie kompatibel) besitzen, einen ATARI ST/TT mit mindestens 2MByte Arbeitsspeicher sowie eine Festplatte, können Sie sich getrost ans Werk machen. Inwieweit Handscanner des europäischen Marktes tauglich sind, konnten wir mangels Testgerät leider nicht erkunden (so gänzlich anders dürften die Geräte nicht sein). Ebenso konnten wir den Versuch nicht wagen, einen als Accessory installierten IDC-Treiber die Ansteuerung eines Handyscanners hilfsweise zu übernehmen, obwohl das Programm ACCs unterstützt.
Installation und Start
Das Kopieren der benötigten Dateien auf die Festplatte erledigt eine Installationsroutine, die uns gleichzeitig fragt, ob wir später Texte der englischen, deutschen, französischen und auch holländischen Sprache abzuarbeiten gedenken. Es werden dabei nämlich alle erforderlichen Lexika auf die Festplatte transportiert. Wenn man nur mit einer Sprache hantiert, spart diese jetzige Abfrage Speicherplatz. Die Benutzung von Deutsch und Englisch beispielsweise setzt mindestens 1,5 MByte freie Plattenkapazität voraus.
Nach erfolgreicher Installation und dem obligatorischen Doppelklick erscheint eine nüchterne, um nicht zu sagen sparsame Oberfläche (siehe auch Bild 4). Es sind zwar insgesamt 11 Schalter( Buttons) links oben zu sehen, aber irgendwie hatte ich doch noch mehr Icons, Schalter und Hinweistäfelchen erwartet. Das war man halt von deutschsprachigen Produkten her gewöhnt.
MIGRAPH OCR ist zwar für das direkte Einscannen von einem Handy ausgelegt, man kann sich dennoch eines Tricks bedienen, wenn eben nur ein ganz normaler Flachbett-Scanner vorhanden ist: Man wählt den Umweg über eine GEM-Image- oder TIFF-Grafik, und genauso haben wir uns dann dem Programm genähert.
Nach dem Laden der Grafik bzw. dem geduldigen Überstreichen eines Dokumentes mit einem passenden Handscanner (und was dabei so alles passieren kann: Kontrast, Helligkeit, wellige Vorlage, Verrut sehen usw.), erscheint die Textseite im Darstellungsfenster. Besitzer eines Großbildschirms sind nun eindeutig im Vorteil, denn MIGRAPH OCR paßt die Größe der Darstellung genau der möglichen Ausdehnung des Bildschirms an. Abgesehen von der 100%-, also originalgroßen und der 2009r-Darstellung, also einer doppelten Vergrößerung, steht noch eine Fullscreen-Funktion, also Ganzbilddarstellung zur Verfügung (deshalb die Anspielung auf den Großbildschirm). Eine Halbgroß-, also 50%-Darstellung wie im Handbuch angedeutet, gab es leider nicht.
Im Rahmen bleiben!
Bei fast allen OCR-Programmen ist es nötig, den Arbeitsbereich zu markieren. So soll damit der reine Text von Bildern oder grafischen Merkmalen getrennt werden. Während bei einigen Programmen nichts läuft, solange kein Rahmen über dem Text aufgespannt wurde, andere sich den Bereich des Textrahmens selbst suchen, überläßt MIGRAPH OCR es einfach uns, ob wir Textbereiche eingrenzen wollen oder nicht.
Das Verfahren der Textrahmen hat durchaus Sinn. So gibt es Vorlagen, die sehr viele Bild- oder Grafikelemente enthalten. Wenn diese nicht ausgrenzbar wären, müßte der Erkennungsalgorithmus diese ebenfalls begutachten, um schlicht festzustellen, daß es halt keine Buchstaben sind (bzw. keine annähernde Ähnlichkeit zu Buchstaben besteht). Der Erkennungsprozeß würde dadurch erheblich länger dauern. Textrahmen haben also den Sinn, dem Erkennungsvorgang zu zeigen, wo ausschließlich sein Revier liegt.
MIGRAPH OCR überläßt es also Ihnen zu entscheiden, ob Sie Textrahmen benötigen oder nicht. Wenn keine Rahmen aufgezogen sind, nimmt das Programm an, die Vorlage bestehe nur aus Text und bezieht sie komplett in den Erkennungsprozeß ein. Und diese Vorgehens weise ist sehr benutzerfreundlich, denn das pingelige Rahmenziehen dauert auch seine Zeit.
Apropos: Wenn Sie nun doch Rahmen ziehen müssen, ist dafür leider nur die Fullscreen-Funktion zu gebrauchen. Die anderen Vergrößerungsstufen sind einfach viel zu groß, um größere Textbereiche überstreichen zu können. Hier hätte ich mir eine stufenlose Vergrößerung oder wenigstens mehr als die zwei Abstufungen gewünscht. Und: in der Fullscreen-Darstellung sind die Einzelheiten einer DIN A4-Seite nur noch sehr schwer zu erkennen (es sei denn. Sie haben einen Großbildschirm - ja, ich bin neidisch).
Kennen Sie den?
Der Erkennungsprozeß gestaltet sieh in MIGRAPH OCR anders, als man von den bekannten Programmen her gewöhnt war. Unmittelbar nach dem Start des Erkennungslaufes wollen die Vergleicher (so nenne ich Programme nach dem Pattern-Matching-Prinzip) sofort einige Buchstaben bestätigt haben, was sich im Laufe des Prozesses in immer selteneren Rückfragen äußert Irgendwann wird man nur noch bei ganz kritischen Zweifelsfällen gefragt - das System hat sich eine größer werdende Zeichenbibliothek angesammelt (die unbedingt für ähnliche Arbeiten abgespeichert werden soll).
MIGRAPH OCR gehört zu den Erforschern (so nenne ich Programme, die nach dem Feature-Sign-Prinzip Vorgehen), die zunächst die Abgrenzungen der separierten Buchstaben nach Ähnlichkeiten aus der Beschreibungsbibliothek absuchen. Hier ist also die intensive Rechen- und Vergleichsarbeit an den Anfang gesetzt. Erst sehr spät, zugegeben, nach einer längeren Wartezeit, fragt das System noch Sonderfälle ab, die auch hier menschlichen Einsatz verlangen.
Bei dieser Arbeit ist mir aufgefallen, daß MIGRAPH OCR zwar durchweg alle Einzelbuchstaben erkannt hat, diese aber dennoch oftmals bestätigt haben möchte. Selbst zusammengewachsene Buchstaben (‘Ligaturen' genannt) wurden verhältnismäßig oft erkannt (siehe auch Bild 6).
In der Riesen-Dialogbox während des Erkennungsvorgangs fallen zwei Besonderheiten auf: Einerseits gibt es eine Automatik, bei der keine Bestätigung abverlangt wird und das System einfach alle Zeichen, auch bei geringster Ähnlichkeit, mit Angaben aus der Beschreibungsbibliothek übersetzt. Dabei kann es natürlich zu Fehlern kommen. Aber immer dann, wenn es sich um eine weitere, gleichwertige Vorlage handelt, kann man mit der Automatik schneller zum Ziel kommen.
Trainingscamp

Die andere Besonderheit verbirgt sich hinter den Begriffen 'Train' (nein, nicht Eisenbahn - Trainieren ist gemeint) und 'Accept' (für Akzeptieren). Mit 'Train' wird das erkannte Zeichen in die Bibliothek aufgenommen, steht also auch für spätere Arbeiten dem „Erfahrungsschatz“ zur Verfügung. ‘Accept' nimmt das Erkennungsmerkmal nur für das vorliegende Dokument zur Kenntnis, speichert es aber nicht ab. Letzteres kann dann recht nützlich sein, wenn die Vorlagenqualität stark von der Normalität abweicht und ähnliche Gegebenheiten für spätere Fälle nicht anzunehmen sind.
Zu dieser Riesen-Dialogbox (Bild 6) noch ein paar Worte: Recht angenehm ist die Dreiteilung der „Erkennungsfensterchen“. Ganz oben ist der laufende Text in fünf Zeilen nachzulesen, darunter steht das gerade bearbeitete Wort, und in der Mitte erkennt man das zweifelhafte Zeichen, das ist auch gleichzeitig das Eingabe- bzw. Bestätigungsfenster. Ein Manko ist die Beschränkung auf maximal 5 Zeichen. Mir ist es doch tatsächlich passiert, daß ein Wort von 6 Zeichen als zusammenhängend deklariert war, da konnte ich aber nicht alle 6 Buchstaben eintippen.
Ein weiteres Manko ist die gleichzeitig nötige Tastatur- und Mausbedienung. Während ich bei der Bestätigungsarbeit viel mit der Tastatur zugange bin (Backspace, Delete, Cursor-Tasten - man kennt das ja), muß ich bei den Befehlen Undo, Delete, Confirm erst nach der Maus suchen. um deren Ausführung zu aktivieren. Hier hätte man sich besser eine zusätzliche Belegung bestimmter Tasten ausdenken sollen. Das ständige Wechselspiel zwischen Tastatur und Mausbewegung ist sehr zeitaufwendig (Ergonomie läßt grüßen). Einzig die 'Train'- bzw. ‘Accept’-Funktion liegt wahlweise auf der Return-Taste.
Wörterbücher, wo seid ihr?
Ungewöhnlich ist, daß man keinen Einblick in und evtl. Einfluß auf die Wörterbücher nehmen kann. Während andere Texterkennungsprogramme sehr stolz die erkannten Zeichen in einer Tabelle präsentieren, bleibt bei MIGRAPH OCR vieles im Verborgenen. Ist ja auch einleuchtend, daß man Formeln und Merkmale, in die die Buchstaben verwandelt sind, schlecht anschaulich darstellen kann, aber die sogenannten ‘linguistischen' Grundlagen (Ausnahmebibliothek) hätte man durchaus offenlegen können.
MIGRAPH OCR bringt schon die Merkmale und Besonderheiten von 21 Zeichensätzen mit: Artisan, Bookman, Brougham, Caroll Pica, Courier, Courier Italic, Delegate, Elite Modem, Helvetica, Harald Elite, Letter Golic, Lori, Lubalin, OCRB, Pica, Prestige Italic, Prestige Pica, Times, Titan und Title. Damit ist fast die gesamte Schriftenpalette üblicher Druckerzeugnisse abgedeckt. Schriftgrößen sollten zwischen 10 und 18 Punkt liegen. Weitere Schriftarten und -großen sind jederzeit möglich und sogar in getrennten Bibliotheken abspeicherbar.
Bedienung bitte!
Ist Ihnen aufgefallen, daß ich bisher die Menüleiste noch nicht erwähnt habe? Um ehrlich zu sein, sie ist auch kaum der Rede wert. Die wichtigsten Funktionen, die in den Menüs versteckt sein könnten, liegen ohnehin außerhalb auf Schaltknöpfen (Buttons) und sind zusätzlich auch noch per Tastenkürzel auslösbar. Also vergessen wir die Menüs gleich wieder - das hätten die Programmierer getrost auch tun können. Nur um gänzlich GEM-konform zu sein, wären die Menüs nicht nötig gewesen. So ist neben dem Darstellungsfenster noch genügend Platz für weitere Buttons.

Geschwindigkeit
Ist Ihnen weiterhin auch aufgefallen, daß ich keine großangelegten Zeitvergleiche mit anderen Programmen angestellt habe? Wie Sie sicherlich den obigen Ausführungen entnehmen konnten, liegt es in der Eigenheit der Erforscher-OCRs, daß sie zunächst viel Zeit durch Mustervergleiche verbrauchen. Bei einem kleinen Text sind garantiert die Vergleicher-OCRs schneller. Außerdem spielen Vorlagenqualität und Geräteeinstellung eine wesentliche Rolle. Ein Vergleicher wird bei einer schlechten Vorlage sofort kapitulieren und die Zeichen per manuelle Eingabe abverlangen. Das bringt ihm aber den Vorteil, weitere ähnliche Zeichen umso schneller finden zu können. Erforscher-OCRs dagegen brauchen bei schlechter Qualität länger, können dafür aber unterschiedliche Größen und Schriftarten in einem gemischten Dokument sofort und ohne Rückfrage erkennen. Ihre „Endgeschwindigkeit“ erreichen sie bei größeren Dokumenten eher.
Bitte haben Sie Verständnis, daß wir an dieser Stelle keine Geschwindigkeitstabelle veröffentlicht haben. Zu Hause haben Sie ganz sicher eine andere Gerätekonfiguration und Ihr Freund Hans wieder eine andere. Es wäre fast ein Vergleich von Birnen mit Äpfeln, und außerdem sind die Geschwindigkeitstests nur subjektiv aussagekräftig.
Rundum
M1GRAPH OCR hat seinen Dienst ohne irgendwelche Probleme erledigt. Es ist großbildschirmfähig. Angenehm ist die fast ausschließliche „Handarbeit“ mit der Maus. Die Lassofunktion zum Einrahmen ist sehr genau. Überdeckende Textrahmen werden automatisch integriert. Das Handbuch von 58 Seiten erklärt die Programmbedienung (in englisch) recht verständlich und hat eine ausreichende Bedilderung. Es geht sehr selten auf theoretische Aspekte der Texterkennung und Scanner-Handhabung ein. Es wird kein Fremd-Scanner-Treiber angeboten. Der Preis von $299 liegt im vertretbaren Rahmen.
Leider gibt es noch keinen deutschen Vertrieb. Dem für ATARI-Systeme neuartigen OCR-Prinzip dürfte (und müßte) auch ein deutscher Markt offen stehen.
DK
Bezugsquelle
Migraph Inc.,
32700 Pacific Highway S.t
Suite 12, Federal Way.
WA 9X003. USA.
Migraph OCR
Positiv:
hohe Trefferquote durch Ähnlichkeitsverfahren
lernfähig, dadurch steigende Geschwindigkeit
sauber in GEM eingebunden
Negativ:
nur in englischer Sprache verfügbar