Was verbirgt sich hinter dem Mysterium "Texterkennung", und wie kann man seinen ATARI dazu bringen, Schriften zu erkennen und diese in weiterverwertbare Textdateien zu wandeln?
Wozu Texte erkennen?
Diese Frage mag sich jeder von uns stellen, der von Texterkennung schon einmal etwas gehört hat. Sinn und Nutzen der Schrifterkennung mittels eines Scanners liegen jedoch auf der Hand: Der Mensch ist schon seit jeher daran interessiert, Arbeitsgänge zu rationalisieren und bestimmte Verfahren zu beschleunigen.
Nicht umsonst heißt es im Volksmund: "Zeit ist Geld".
Stellen Sie sich folgende Situation vor: Sie erhalten einen Mustervertrag, z.B. per FAX, der rund 16 Seiten lang ist. Diesen Vertrag möchten Sie für ein eigenes Vorhaben verwenden, müssen jedoch die darin eingetragenen Daten durch Ihre eigenen ersetzen und einige andere Kleinigkeiten modifizieren. Sie haben nun folgende Möglichkeiten:
a) Sie tippen den gesamten Text ab. Wenn Sie jedoch nicht unendlich viele Anschläge pro Minute realisieren können, verlieren Sie viel Zeit. Außerdem laufen Sie Gefahr, unnötige Tippfehler einzubauen.
b) Sie bedienen sich eines Scanners, lesen die 16 Seiten komplett in den Rechner ein und lassen die Texte nun durch ein Schrifterkennungsprogramm in eine Textdatei wandeln, die Sie wiederum bequem in eine Textverarbeitung einladen und dort Ihren Wünschen entsprechend verändern können.
Diese Methode ist mit Sicherheit die schnellere und bequemere!
Was heißt Texterkennung?
Unter Texterkennung versteht man die Umwandlung eines in grafischer Form gegebenen Textes in eine codierte Form (z.B. ASCII-Format). Text in grafischer Form bedeutet wiederum, dass eine Textseite von einem Scanner abgetastet als gesamtes Bild vorliegt, also als Matrix mit schwarzen und weißen Punkten. Die Aufgabe einer Texterkennungssoftware ist es nun, einzelne Buchstaben zu separieren und diese mit einem vorgegebenen Muster zu vergleichen. Wird eine separierte Form als ein Buchstabe wiedererkannt, kann das Programm eine Wandlung vornehmen und sich dem darauffolgenden Zeichen widmen.
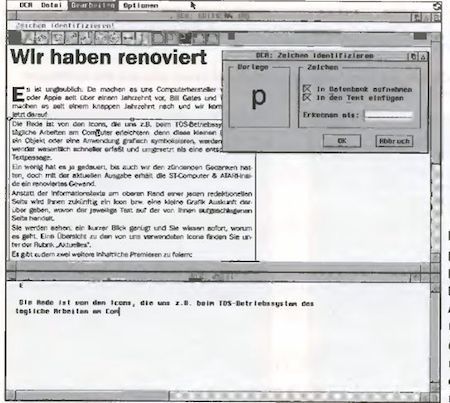 Bild 1: In unserem Test haben wir das Editorial der letzten Ausgabe gescannt und erkennen lassen. Oben die IMG-Graflk und unten die ersten erkannten und umgesetzten Zellen.
Bild 1: In unserem Test haben wir das Editorial der letzten Ausgabe gescannt und erkennen lassen. Oben die IMG-Graflk und unten die ersten erkannten und umgesetzten Zellen.
Folgende Faktoren müssen jedoch eingehalten werden, damit eine korrekte Funktion gewährleistet ist:
- Der Text muss gedruckt sein, so dass gleiche Buchstaben immer ein gleiches-Aussehen haben.
- Buchstaben sollten nicht zu sehr verwachsen sein. Dies passiert, wenn diese ohnehin sehr eng aneinandergereiht sind und durch eine schlechte Druckvorlage oder einen schlechten Scan keine klaren, weißen Trennlinien zwischen den einzelnen Buchstaben sind, so dass der Rechner eine Buchstabenkombination als ein Zeichen erkennt.
Je einheitlicher und klarer der Text also ist, desto weniger Fehler macht eine Texterkennungssoftware.
OCR 1.4
Dieses Programm stammt von dem Programmierer Alexander Clauss, der auch schon für den hervorragenden HTML-Browser CAB verantwortlich ist. Es ist Freeware, kostet also keinen Pfennig und ist vielen ATARI-Usern seit Jahren eine große Hilfe bei der Texterkennung.
Das Programm OCR ist in der Version 1.4 sehr vielseitig und dem aktuellen Standard angepasst. Die Bedienung ist in der Regel äußerst einfach, so dass sich der Anwender innerhalb weniger Minuten einarbeiten kann.
Wie OCR Texte erkennt
OCR hat diverse Möglichkeiten, Texte zu erkennen. Die für Schrifterkennungssoftware allgemein übliche Art ist die der Einzelidentifikation. Nach dem Start des Programmes laden Sie ein Monochrombild ein. In unserem Fall haben wir aus der letzten ST-Computer & ATARI-Inside das Editorial mit 300 dpi eingescannt, was zugegebenermaßen ein relativ hoher Wert ist, den man bei dem Scan eines Faxes nicht erreichen kann.
Nun ermittelt das Programm eigenständig die erste Zeile, indem es nach mindestens einer leeren weißen Linie sucht. Anschließend werden die einzelnen Buchstaben separiert und mit den in der Datenbank befindlichen Fonts verglichen. Man sollte hierbei darauf achten, dass keine falsche Font-Bibliothek geladen ist, da es ansonsten zu Falscherkennungen kommen kann.
Ist keine Bibliothek geladen oder vorhanden, fragt das Programm jeden einzelnen Font ab (siehe Bild 1). Bei eingeschaltetem Lernmodus kann der Anwender nun in einer Dialogbox das dazu passende Zeichen über die Tastatur eingeben. Zur Orientierung wird das erfragte Zeichen sowohl in der Dialogbox (die sich übrigens auch ausschalten lässt) angezeigt als auch auf dem Bildschirmausschnitt markiert. Da es vorkommen kann, dass OCR keine klare Trennung zwischen den einzelnen Zeichen registriert, taucht hin und wieder eine Anfrage für eine Buchstabenkombination auf, die mit bis zu elf Zeichen vom Anwender identifiziert werden kann (siehe Bild 2).
Die Prozedur geht so vor sich, dass das Programm verständlicherweise anfangs noch jeden einzelnen Buchstaben abfragt, sich aber im Laufe der Zeit immer mehr Buchstaben merkt, so dass nur noch vereinzelt Fragen auftauchen. Ein mit OCR erkannter Font kann als solcher auch abgespeichert werden, so dass beim Erkennen umfangreicher Texte, deren Bearbeitung sich über mehrere Tage erstreckt, nicht nach jedem Start wieder die Buchstaben neu erkannt werden müssen.
Sinnvoll ist dies z.B. auch, wenn man aus periodisch erscheinenden Printmedien bestimmte Teile einlesen möchte. Wir haben bei unserem Testbild die Stoppuhr zu Hilfe genommen und das gescannte Editorial nach dem ersten Durchgang, also nachdem OCR alle Buchstaben und Schriftzeichen kannte, komplett neu erkennen lassen.
Dies dauerte für die gesamte Seite rund 1.15 Minuten (gemessen auf einem ATARI Mega STE mit 16 MHz).
Da die Anzahl der Worte dieses Editorials in etwa der einer durchschnittlichen Taschenbuchseite entspricht, könnte man ein ganzes Werk in rund 2 Stunden erkennen lassen (von der Zeit fürs Scannen, Speichern und Laden einmal abgesehen).
Für Bilder aus Zeichenprogrammen oder Bildschirmkopien von Texten, die mit GDOS-Zeichensätzen geschrieben wurden, besitzt OCR 1.4 einen schnellen Modus. Hierzu muss lediglich der in dem Bild verwendete Zeichensatz ausgewählt werden.
Ein Erlernen der Fonts entfällt, da das Programm diese Fonts bereits "kennt".
Möglichkeiten der Bearbeitung
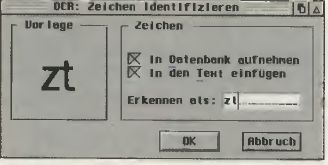 Bild 2: Verkettete Erkennungen mit bis zu elf Buchstaben sind Identlfizierbar.
Bild 2: Verkettete Erkennungen mit bis zu elf Buchstaben sind Identlfizierbar.
Es ist unabwendbar, dass Scans auch Fehler aufweisen oder teilweise unpräzise sind. Damit es aber dennoch nicht zu vielen zeitintensiven Unterbrechungen bei der Texterkennung kommt, besitzt OCR eine Vielzahl von Einstellungs- und Bearbeitungsmöglichkeiten. Die wichtigsten globalen Einstellungen sind über die Menüleiste vorzunehmen, die nach dem Laden einer Grafik sichtbar wird (Bild 3).
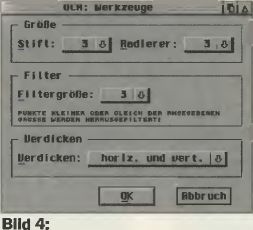
Über diese Leiste können Sie das geladene Bild sowohl verkleinern als auch vergrößern. Ein Stift und ein Radiergummi ermöglichen das nachträgliche Bearbeiten von kritischen Stellen eines Scans. So können unschöne Flecken, die ebenfalls eingescannt wurde entfernt werden, damit eine Nachfrage, um welchen Font es sich dabei handle, entfällt.
In diesem Zusammenhang besitzt OC 1.4 auch eine schöne Filterfunktion, deren Parameter ebenso wie die des Radierers über die Werkzeugeinstellungen modifiziert werden können (Bild 4). Hierbei können Sie bestimmen, dass jeder Punkt oder Fleck, der bis maximal 3 x 3 Punkte groß ist, aus dem Bild gefiltert wird.
Interessant ist die Funktion "Glätten", die unschöne Treppen entfernt und das Erkennen der Schriften somit erleichtert.
Weitere Möglichkeiten sind das Spiegeln und Drehen der geladenen Grafik, so dass der Einsatz einer externen Bildbearbeitungssoftware in der Regel nicht notwendig ist.
 Bild 3: Die Menüleiste von OCR 1.4. die beim Laden eines Bildes aktiviert wird und die wichtigsten Funktionen zur Bildbearbeitung anbietet.
Bild 3: Die Menüleiste von OCR 1.4. die beim Laden eines Bildes aktiviert wird und die wichtigsten Funktionen zur Bildbearbeitung anbietet.
Vor dem Start der Texterkennung sollte man nun noch einige grundlegende Parameter einstellen. Diese betreffen z.B. die Anforderungen an die Übereinstimmung der einzelnen von OCR erkannten Zeichen. Je besser die Qualität der gescannten Grafik ist, desto höher kann man diesen Wert stellen. Damit kann man die Fehlerquote erheblich verringern. Aber auch Werte zur Schräge eines gescannten Bildes können in diesem Dialogfenster editiert werden, so dass eine individuelle Konfiguration zu jedem verwendeten Bild möglich ist. Der Bereich, der innerhalb einer gescannten Seite erkannt werden soll, kann mittels eines frei definierbaren Rahmens angegeben werden. In Bild 1 sehen Sie, dass wir nicht den gesamten Text, sondern nur den Bereich unterhalb des ersten Absatzes haben erkennen lassen.
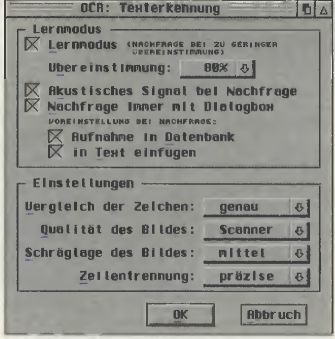 Grundeinstellungen, die man bei OCR vor dem Erkennen einer Textgrafik vornehmen sollte.
Grundeinstellungen, die man bei OCR vor dem Erkennen einer Textgrafik vornehmen sollte.
Eine künstliche Intelligenz?
Beeindruckend bei Texterkennungssoftware ist auf jeden Fall die Lernfähigkeit, wenngleich diese auf einfachsten mathematischen Regeln beruht. Bei OCR 1.4 kommt eine weitere nützliche Funktion hinzu, die den Eindruck einer Softwareintelligenz vermittelt:
Eine Texterkennung kann, wie oben beschrieben, nicht immer perfekt verlaufen. So sind bei vielen nicht serifen Zeichensätzen selbst mit bloßem Auge kaum Unterschiede zwischen einem großen "1" und einer "Eins" zu erkennen. Kommt hierzu noch ein wenig Ungenauigkeit seitens des Scanvorgangs, ist die Erkennungssoftware aufgeschmissen. OCR 1.4 verfügt über eine Korrekturfunktion, die die Umgebung eines so zweideutigen Zeichens betrachtet und prüft, welches Zeichen am wahrscheinlichsten ist. So wird es nie vorkommen, dass OCR in einem Zweifelsfall in eine Reihe von Zahlen ein großes "1" einfügt.
Aufmachung
Das Programm ist, wie eingangs erwähnt, modern und den heutigen Anforderungen angepasst. So unterstützt es unter MagiC 5 auch lange Dateinamen, unter MultiTOS das Drag&Drop-Protokoll, den 3D-Effekt der Dialogboxen und läuft auf allen gängigen ATARI-Rechnern und Emulationen ab 1 MB-RAM, wobei man bedenken sollte, dass gescannte Grafiken häufig speicherintensiv sind (2 MB empfohlen).
 Feinabstimmung für bestmögliche Texterkennung.
Feinabstimmung für bestmögliche Texterkennung.
Fazit
Mit OCR 1.4 macht das Texterkennen wirklich Spaß. Einige kleine Wünsche, die momentan noch unerfüllt sind, sollen aber in zukünftigen Versionen nachgereicht werden.
Hierzu gehört z.B. das automatische Abarbeiten mehrerer Seiten, also eine Art JOBFunktion. Hierbei wird man OCR angeben, welche Grafiken es einladen und bearbeiten soll, um den Rechner daraufhin eine ganze Nacht lang "schuften" zu lassen.
In diesem Zusammenhang wird es auch möglich sein, die Nachfragen, die trotz kompletter Fontbibliotheken auftauchen können, an das Ende der Erkennungsprozedur zu legen.
Auch soll es in Zukunft möglich, sein, mehrere Zeichensatz-Datenbänke gleichzeitig zu verwalten, damit auch gescannte Seiten, die verschiedene Schrifttypen enthalten, problemlos bearbeitet werden können.
Bezugsquelle:
- Mailboxen
- FTP-Server
- PD-Serie
- aktuelle Spezial-Diskette Nummer 4/97
oder beim Autor:
Alexander Clauss
Stresenlannstr. 44
64297 Darmstadt